
When the term IP first came into popular usage for IC design, it was primarily conceived as blocks of design content that were bought occasionally from external sources. A customer might use one or two in a design, and expect one delivery with perhaps some minor updates before tapeout. Over the last 18 years, this notion has changed quite a bit as design complexity has increased and the level of integration required for SOC development has risen dramatically.
What have we learned in the intervening years? For one thing, IP is frequently developed internally as well as externally. So, IP management and release systems are not just for so-called IP providers anymore. Furthermore, the necessities of design reuse have formalized a lot of the processes regarding sharing of design blocks internally. It’s easy to think of it still being a matter of just freezing a design block and handing it off as being a workable method of releasing IP. However, this is far from the case.

Methodics recently posted an article on their website that peels the onion regarding the issues related to developing a truly effective way of developing and releasing IP. Here are some of the key messages in this article.
Because IP’s are essentially design blocks, they possess a variety of views, some of which have their own independent release criteria. Good examples are documentation, schematics, RTL, layout, test files, generated views for external processing steps, etc. The list of view types is vast. Each view type can have its own release schedule and dependencies. Lumping them all together in the IP management system can cause inefficient course grain data management.
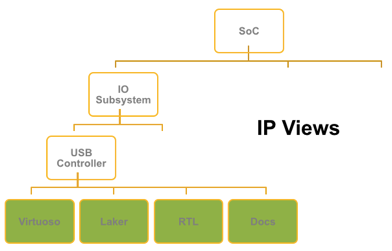
Internally during development of IP there will be a variety of people who work on the IP. But they each may work in different domains and do not have a need to populate their workspace with all the files in the IP. They need a way to selectively populate their workspace with just the entities they need to do their job.
Because different view types will inevitably pass regression tests out of sync with each other, IP developers will often need to have selected versions of certain views in their workspaces so they can work with known good versions. This may vary from user to user. Additionally, in some cases designers may want the latest version of the layout data, which is in flux, but also reference a specific version of the schematic for instance. Just grabbing a single release of the physical design view will not accomplish this.
It gets even more interesting when you add in the dependency checks to ensure that the data all represents a consistent flow from start to finish. It can be a big problem if the RTL is newer than the gate level data for instance. Or another example is where the verification output is older than the design data it is derived from.
At the end of the Methodics article they discuss how they have implemented their MDX_VIEWS to dynamically allow for easily setting up all the views needed for an IP release in such a way that all the needs are met and the data is consistent. I won’t spoil this for you, but instead refer you to the article on the Methodics website.
What is clear from reading their blog, is that they have encountered many real world large team design problems and have been able to effectively devise features in their software to accommodate these needs.
Follow the adventures of SemiWiki on LinkedIn HERE!
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.