
 Intelligence as in the term artificial intelligence (AI) involves learning or training, depending on which perspective it is viewed from –and it has many nuances. As the basis of most deep learning methods, neural network based learning algorithms have gained usage traction, when it was shown that training with deep neural network (DNN) using a combination of unsupervised (pre-training) and subsequent supervised fine-tuning could yield good performance.
Intelligence as in the term artificial intelligence (AI) involves learning or training, depending on which perspective it is viewed from –and it has many nuances. As the basis of most deep learning methods, neural network based learning algorithms have gained usage traction, when it was shown that training with deep neural network (DNN) using a combination of unsupervised (pre-training) and subsequent supervised fine-tuning could yield good performance.
A key component to the emerging applications, AI driven computer vision (CV) has delivered a refined human-level visualization achieved through the application of algorithm such as DNN to convert digital image data to a representation understood by the compute engine –which is increasingly moving towards the network edge. Some of the mainstream CV applications are embedded in smart cameras, digital surveillance units and Adaptive Driver Assistance Systems (ADAS). 
DNN has many variations and it has delivered remarkable performance for CV related tasks such as localization, classification and object recognition. Applying DNN data driven algorithm for image processing is computationally intensive and requires special high speed accelerators. It also involves performing convolutions. A technique frequently used in digital signal processing field, convolution is a mathematical way of combining two signals (the input signal and an impulse response of a system, containing information as to how an impulse decays in that system) to form a third signal, which is the output of these convolved signals. It reflects how the input signals impacted in that system.
The design target and its challenges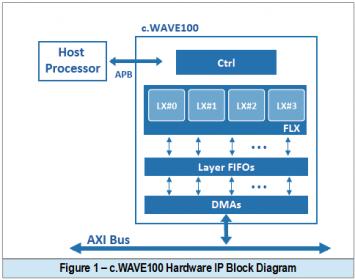
As a leading provider of high-performance video IP, Chips&Media™ developed and deployed various video Codec IPs for a wide range of standards and applications, including fully configurable image signal processing (ISP) and computational photography IP.
The company most recent product, a computer vision IP called c.WAVE100 is designated for real time object detection and processing of input video at 4K resolution and 30fps. Unlike the programmable software based IP approach, the team goal was to deliver a PPA-optimal hardwired IP with mostly fixed DNN (with limited runtime extensions). The underlying DNN based detection algorithm was comprised of MobilNets, Single Shot Detection (SSD) and its own proprietary optimization techniques.
The selection of MobileNets on top of an optimized accelerator architecture that employs depthwise separable convolutions is intended for a lightweight DNN. The four layer architecture consists of two layers (LX#0, LX#2) intended for conventional and depthwise convolution, and another pair (LX#1, LX#2) for pointwise convolution as shown in figure 2. On the other hand, SSD is an object detection technique using a single DNN and multi-scale feature maps.
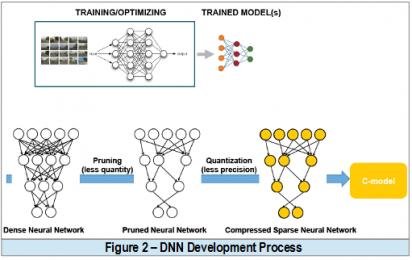
As a DNN-based CV processing is inherently repetitious, evolving around the MAC unit –with massive data movement through the NN layers and FIFOs, the team objective was to have a tool that allows a rapid architectural exploration to yield an optimal design and shorten development time for time-to-market. The DNN based model was then trained using large dataset on TensorFlow™ deep learning frameworks. As illustrated in figure 3, the generated model was to be captured in C language format and synthesize into RTL.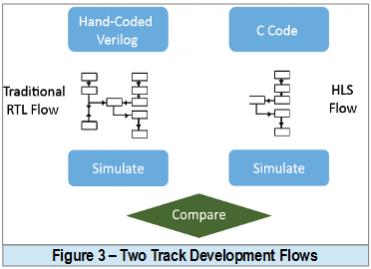
In order to fairly assess the effectiveness of an HLS based solution versus the conventional RTL capture approach, two concurrent c.WAVE100 IP development tracks were assigned to two different teams. Such arrangement was done to mitigate risk of not disrupting the existing production approach which relies on manual Verilog coding captures. Furthermore, none of team members have prior exposures to the HLS tool or flow.
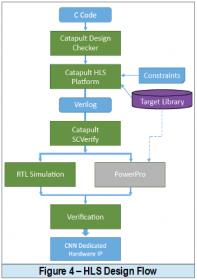 The team selected the Catapult® HLS Platform from Mentor as it provides algorithm designers a solution to generate high-quality RTL from C/C++ and/or SystemC descriptions that is targetable to ASIC, FPGA, and embedded FPGA solutions. A big plus on the feature side includes the platform ability to check the design for errors prior to simulation, its seamless and reusable testing environment, and its support to formal equivalence checking between the generated RTL and the original source. A power-optimized RTL, ready for simulation and synthesis can be rapidly generated through Catapult using the flow as shown in figure 4.
The team selected the Catapult® HLS Platform from Mentor as it provides algorithm designers a solution to generate high-quality RTL from C/C++ and/or SystemC descriptions that is targetable to ASIC, FPGA, and embedded FPGA solutions. A big plus on the feature side includes the platform ability to check the design for errors prior to simulation, its seamless and reusable testing environment, and its support to formal equivalence checking between the generated RTL and the original source. A power-optimized RTL, ready for simulation and synthesis can be rapidly generated through Catapult using the flow as shown in figure 4.
In addition to a shortened time to market at lower development cost, there are 3 key benefits pursued by the team:
– To enable a quick late-stage design changes at C/C++ algorithm level, regenerate the RTL code and retarget to a new technology.
– To facilitate what-if, hardware and architecture exploration for PPA without changing the source codes.
– To accelerate schedules by reducing both design and verification.
Flow comparison and results
At the end of the trials, the team made a comparison of the two flows as tabulated below:
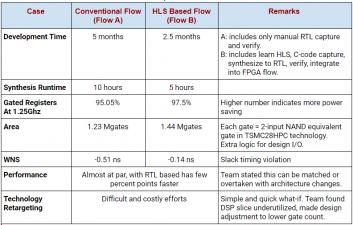
The team takeaways from this concurrent development and evaluation efforts on design with HLS vs traditional RTL methods are as follows:
- Easy to convert algorithmic C models to synthesizable C code. Unlike RTL, there was no need to write FSMs or to consider timing between registers. The C code was easier to read for team code reviews and the simulation time was orders of magnitude faster.
- Optionally easy targeting on free software like gcc and gdb in order to quickly determine if the C code matched the generated RTL.
- Ability to exercise many architectures with little effort using HLS, which otherwise was very difficult to do in the traditional RTL flow.
- SCVerify is a great feature. There was no need to write a testbench for RTL simulation and the C testbenches were reusable.
To find more details on this project discussion check HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.