Arteris IP recently spoke at the Spring Linley Processor Conference on April 21, 2021 about Automotive systems-on-chip (SoCs) architecture with artificial intelligence (AI)/machine learning (ML) and Functional Safety. Stefano Lorenzini presented a nice contrast between auto AI SoCs and those designed for datacenters. Never mind the cost or power, in a car we need to provide near real-time performance for sensing, recognition and actuation. For IoT applications we assume AI on a serious budget, power-sipping, running for 10 years on a coin cell battery. But that isn’t the whole story. AI in the car is a sort of hybrid, with the added dimension of safety, which makes for unique architecture wrinkles in automotive AI.
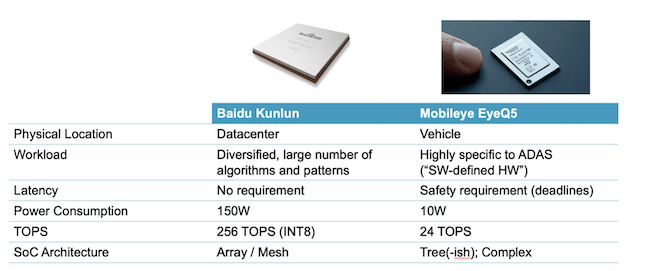
I’ve mentioned before that Arteris IP is in a good position to see these trends because the network-on-chip (NoC) is at the heart of enabling architecture options for these designs. Currently Arteris IP is in the fortunate position to be the NoC intellectual property (IP) of choice in a wide range of hyperscalar and transportation applications, particularly those requiring AI acceleration. For example, Baidu with their Kunlun chip for in-datacenter AI training versus Mobileye with their EyeQ5 chip targeted at mobile autonomy for levels 4 and 5. Each is quite representative of its class, in constraints and architecture choices, granting that AI architecture is a fast-moving domain.
Datacenter AI Hardware
All hardware is designed to optimize the job it must do. In a datacenter, that can be a pretty diverse spectrum of pattern recognition algorithms. Therefore training/inference architectures most often settle on arrays of homogenous processing elements, where the interconnect is a uniform mesh between those elements (perhaps also with E/W sides or N/S sides connected).
These architectures must process huge amounts of data as fast as possible. Datacenter services and competitiveness are all about throughput. The accelerator core will often connect directly to high bandwidth memory (HBM) in the same package for working memory to maximize throughput. The design includes necessary controller and other SoC support but is dominated by the accelerator.
Performance is king, and power isn’t a big concern, as you can see in the table above for the Kunlun chip.
Automotive AI Hardware
Automotive AI is also designed to optimize the job it must do, but those tasks are much more tightly limited. It must recognize a pedestrian, lane markings or a car about to pass you. Such designs need to be more self-contained, handling sensors, computer vision, control, potentially multiple different accelerators, plus an interface to the car network. A more heterogeneous design with a mesh network won’t help.
Even within the accelerators, arrays of processing elements with mesh networks are far from ideal. Architects are shooting for two things: lowest possible power and lowest possible latency for safety. Both of which you can improve by keeping as many memory accesses as possible on-chip. Local caches and working memories must be distributed through the accelerator. Array/mesh structures are also not ideal for latency. These structures force multi-hop transfers across the array where an automotive application may want to support more direct transfers. An array of processing elements is often overkill. A more targeted structure no longer looks like a neat array.
You can further reduce latency through broadcast capabilities. These fan out critical data across the network in one clock tick, becoming faster by departing yet further from that simple array/mesh structure.
By default, AI accelerators are power hogs. Huge images are flowing through big arrays of processors, all constantly active. Dedicated applications can be much more selective. Not all processors or memories have to be on all the time; they can be clock gated. You can also selectively clock gate the interconnect itself. This is an important consideration because there can be a lot of long wires in these interconnects. You can manage dynamic power through careful design. Augmenting this with intelligent prediction of what logic you want on and when.
Automotive AI and Safety
Safety isn’t a big consideration in datacenter AI hardware, but it’s very important in auto applications. All that extra memory on-chip needs error code correction (ECC) to mitigate the impact of transient bit flips, which will likely further complicate timing closure. Typically, safety mitigation methods will increase area and may negatively impact yield.
More generally, Kurt Shuler, vice president of marketing at Arteris IP, likes to say that an SoC (micro-)architect should pay close attention to any project management topic in safety which might impact architecture. Safety-critical designs start with pre-agreed lists of Assumptions of Use (AoU) from IP suppliers. If they start checking these late in design, they can get into a lot of trouble. They need to understand these AoUs up-front as you are developing the architecture. These are things suppliers can’t change easily. Save yourselves and your suppliers all that hassle. Read the instructions up front!
You can access the Linley presentation HERE.
Also Read:
Arteris IP Contributes to Major MPSoC Text
SoC Integration – Predictable, Repeatable, Scalable
Arteris IP folds in Magillem. Perfect for SoC Integrators
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.