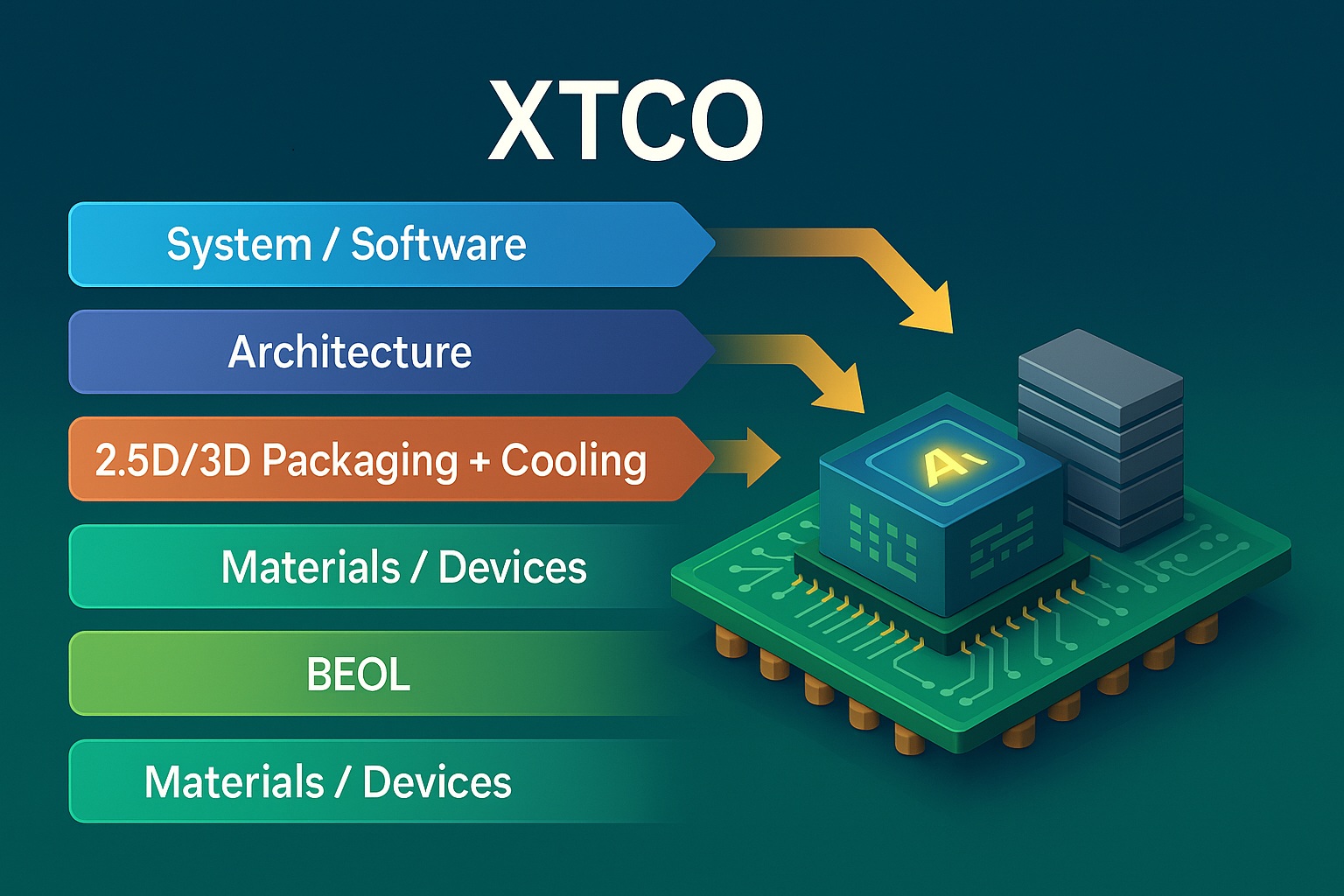



imec XTCO (Cross-Technology Co-Optimization) is the natural successor to DTCO and STCO in an era where no single layer of the stack can deliver scaling alone. Instead of optimizing devices, interconnect, packaging, architecture, and software in isolation, XTCO treats them as one tightly coupled system with a shared budget for performance, power, area, cost—and increasingly, embodied energy. The premise is simple but powerful: you don’t “win” PPAC by improving a transistor or a router hop in a vacuum; you budget PPAC across layers, guided by real workloads and realistic manufacturing constraints.
The XTCO loop starts with workload-anchored targets. Latency, throughput, perf/W, power envelopes, and cost per good system are stated up front, often with thermal and reliability ceilings. From there the program explores architectural partitioning—monolithic die versus a graph of chiplets; how many HBM stacks; whether to place last-level cache as 3D SRAM; what fabric topology and link widths to adopt. Each partition implies different stress on the power delivery network, different heat flux patterns, and different yield arithmetic. XTCO keeps those implications visible while decisions are still cheap.
Next, teams pick technology option sets: device flavors (nanosheet, forksheet, CFET), BEOL stacks and via rules, backside power delivery, and 2.5D/3D packaging choices such as silicon interposers, bridges, hybrid bonding, or fan-out panel flows. Thermal solutions—air, vapor chamber, cold plate—are treated as first-class technology knobs, not afterthoughts. The method insists on co-simulation: timing with realistic interconnect RC, SI/PI with package parasitics, thermal fields with activity factors from the actual software, and yield/cost with compounded probabilities across dice, interposers, and assembly. What emerges isn’t a single “answer” but a ranked set of feasible corners with quantified risk.
XTCO’s most practical contribution is hierarchical budgeting. Instead of over-guardbanding everywhere, the program assigns tight margins where models are confident and reserves slack where uncertainty is high. For example, you might trade a denser BEOL option for a cooler that shaves 10–15 °C at the hotspots, which in turn relaxes voltage guardbands and timing derates. Or you might accept a slightly larger die if a simpler PDN flattens IR drop and shortens schedule. XTCO surfaces these trades transparently in a techno-economic dashboard: energy per task (or per token), perf/W, cost per good module, thermal headroom, schedule risk, and supply-chain sensitivity.
The approach shines in chiplet programs. Reticle limits and yield realities push large systems toward multi-tile logic with multiple HBM stacks. But chiplets aren’t a free lunch: link power, latency, synchronization, and package routing all tax the budget. XTCO asks whether links can move from SerDes-like PHYs to short-reach die-to-die fabrics; whether hybrid bonding eliminates energy per bit enough to justify process complexity; whether a glass substrate or panel flow reduces warpage and improves assembly takt time. Crucially, it forces known-good-die and known-good-interposer assumptions into the cost model, preventing surprises at bring-up.
Organizationally, XTCO is as much process as it is technology. It demands shared data models between device, package, and system teams; early availability of packaging/cooling PDKs; and a steady cadence of risk burndown vehicles—small test chips or thermal coupons that retire the riskiest assumptions first. It also calls for decision hygiene: which metrics decide, who owns the budget, and how often the stack is re-balanced as software or supply conditions change.
XTCO is not without friction. Model fidelity can lag exploration speed. Packaging toolchains are less standardized than front-end flows. And the supply chain—from foundry to OSAT to cooler vendors—must be synchronized so a single slow takt doesn’t cap the whole program. Yet the payoff is decisive: predictable delivery of systems that meet PPAC targets with fewer late-stage pivots, and a roadmap where scaling comes from coordination, not just shrink. In short, XTCO turns optimization into a contract across the stack—and that contract is how modern systems ship on time and on budget.
Share this post via:



Intel, Musk, and the Tweet That Launched a 1000 Ships on a Becalmed Sea