I came across an interesting white-paper from ST Ericsson on two topics: multi-processors in mobile platforms and FD-SOI. FD-SOI is the ST Microelectronics alternative to FinFETs for 20nm and below. It stands for Fully-Depeleted Silicon-on-Insulator. But I’m going to save that part of the white-paper for another blog entry and focus on the mobile stuff here. By the end of this blog entry you will see why these two seemingly disconnected topics are in a single white paper.
Multi-core originally was driven by the realization in the PC market by Intel that the power density of their processors was going to surpass that of the core of a nuclear reactor if they just kept upping the clock rate. Instead, increased computing power would have to be delivered not by a single core with more performance but by multiple cores on the same die.
Initially this worked well since it was not hard to make good use of dual cores, one doing compute intensive stuff and one being responsive. But more cores turned out to be really hard to make use of (not a surprise to software type like me since making a big computer out of lots of little cheap ones has been a major area of research for many decades). Ten years later, most software including games, office productivity, multimedia playback, web browsing etc only make use of two cores. Just a few applications such as image and video processing have very easily partitioned algorithms that can make use of almost arbitrary numbers of cores.
In mobile the multi-core change has come faster since the same power considerations are more urgent. The cliff was not that people couldn’t have a nuclear reactor in their pocket but that pushing the clock rate up too high killed battery life and so multi-core was a way of getting that back up again.
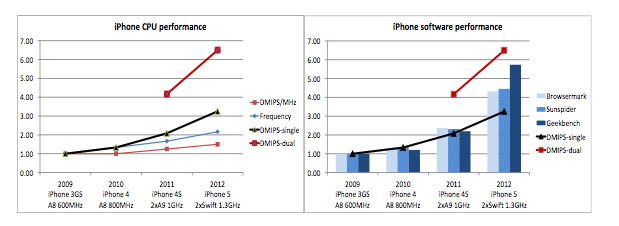
But look as a close reading of the above graphs shows, single core performance isn’t, in fact, saturated at all and there is still strong acceleration. This is totally different from PCs which were clearly saturated very early. But, as for the PC, software only scales with single processor performance and less than proportionally (or, depressingly, not at all) for multiprocessors.
So why have mobile platforms jumped into multi-core well before reaching saturation on the first core. One is that it could piggy-back on existing experience since it was already known that dual cores could be exploited well by operating systems and the fundamental technologies such as cache-coherence (and how to build them on silicon) were well understood. And the other is aggressive marketing (“mine’s bigger than yours”).
What is unclear is why the major platforms have gone to 4 cores (or 8 the way Samsung counts) since the PC experience already shows that more than two processors is useless for most things (and people aren’t running photoshop on their phones). It turns out that there are no strong technical reasons, it seems to be entirely down to marketing since the number of processors is used for differentiation, even for the end-user (who, generally, wouldn’t know what a core was if you asked them, is it something to do with the center of the Apple?).
For web browsing, especially with HTML5 rich content, processing speed is often the critical path rather than the network bandwidth (my LTE iPad downloads faster than my Mac iBook since LTE is faster than my wireless router). You can see from the above picture that going to dual core gets 30% speedup going from single to dual core, but 0-11% from dual to quad.
On the other hand, frequency improvements always pay off. 1.4GHz dual core beats 1.2GHz quad core. In all the experiments STE have done, the results are the same. No benefit in going from dual core to quad core and 15-20% faster dual core always beating slower quad core.
What this means is that increasing the frequency of the processor at constant power is more important than adding cores. This is where the FD-SOI part comes into play. Using process technology to get the frequency up 15% is better than adding cores beyond two.
Download the white paper here.
Also read: FD-SOI worth more than two cores