Qualcomm buckles up for 4G machine communications and the technologies it has picked hint on the most likely winners in the crowded space of the Internet of Things (IoT) standards for machine-to-machine (M2M) communications.
Continue reading “Cellular Meets IoT in Qualcomm’s New LTE Push”

Will the Snapdragon 820 Overheat?
So, I happened to read an article today about overheating issues on the snapdragon 820 from rather flaky sources. To guess the answer to this question, one has to understand the snapdragon 810 “heat-gate” and the sequence of events that led to it.
Continue reading “Will the Snapdragon 820 Overheat?”
How to Live with Rapid Changes During Early Development of IP
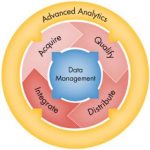
Best practices call for using a version control system with systematic releases when developing IP. However, in the early stages of IP development using a rigid version control system with a cumbersome release process can hinder productivity. To fully understand how this works we should start by defining what is meant when we say IP.
The term IP is used broadly in IC design. It can refer to libraries, memory blocks, or portions of a design coming from internal or external organizations. Furthermore, blocks developed using IP may themselves become IP for higher level design. In this case the lower level IP are referred to as IP resources.
Methodics has thought through the implications of developing and using IP early in a project’s lifecycle. This stage is characterized by rapid changes and short loop iteration. If each time a work in progress change is made early on in the development process, it was necessary to create a release, the entire work flow will be slowed down. To solve this problem Methodics supports a specification that uses the most recent version of the files to populate a workspace. This is known as IP@HEAD.
There are a number of subtleties in its usage. They key point being that loading a workspace with IP@HEAD will pull in the then current versions of not only the IP itself but the resources the IP relies on. Additionally, if the IP resources are themselves running on an orderly release system, as opposed to @HEAD, then the most recent release will be what are loaded. A release update of an IP resource will update the user’s workspace that is using @HEAD.
The history of design management in the IC space is a long and checkered one. It is definitely a different problem than source code revision control management. Designers have balked at systems that impose restrictions on their method of operation. The cost benefit-trade off is most difficult to justify at the beginning of a project, especially if the design management system is imposing unneeded and inefficient processes.
Later as a design matures, the benefits are more readily apparent and design management provides some huge wins for reliability, quality, repeatability and traceability. When a design starts by using IP@HEAD for its workspaces, as the design matures a release methodology can be put in place so there is less uncertainly as functionality is stabilized.
Methodics has built a sophisticated IC centric data management system. One of the plusses of their system is that it is based on industry standard revision control systems like Perforce and Subversion. This means that the design data will never be locked in. Their infrastructure also enables multisite sharing, disaster recovery and design progress analytics.
If you want more information on using IP@HEAD in Methodics, please look here. For more general information about Methodics their website offers useful information.
Follow the adventures of SemiWiki on LinkedIn HERE!
How Can Big Data and EDA Tools Help?

Big data is a headline phrase that I see appear almost weekly now in my newsfeed, so it’s probably time that I start paying more attention to the growing trend because it does impact how technology-driven, EDA tool flows are being used. From my last trip to DAC I recall only two companies that were really focused on system-level design, which is a ripe application area to start mining and controlling big data while building an electronics-based system. Michael Munsey is an expert in system-level design and works at Dassault Systemes, so I went back to a conversation that Michael had in August about the topic of EDA and big data.
Q: As an overview, just what does Dassault have to offer?
So at Dassault Systemes we’re known as the 3D experience company. We started off as a 3D CAD company, and then brought in other pieces of technology like a PLM system, some multi physics modeling solutions, and we’ve grown over the years to actually encompass twelve brands across twelve different industries.
In the past couple of years we’ve been really focusing on the semiconductor industry because we’ve seen that there are a lot of system level issues that have been solved in other industries that we serve. Industries like the transportation, mobility, automotive, aerospace and defense. We have solutions that have worked very well for those industries for many, many years. We’re working on taking those solutions and creating a semiconductor solution based off of this proven technology and now we’re rolling it out to the semiconductor industry.
Q: What is happening with big data and EDA tool flows today?
The biggest challenge right now is that data is only as good as what you have available. Now we’ve seen a lot of people talking about capturing design data and performing big data analytics on it. That works, provided that you have all the data.
What we’ve seen however, is that it’s very difficult for companies to come up with processes in place to capture everything that they need to capture. Design companies have multiple tools in the EDA flow chain, in different domains and you also have system tools. You have functional verification tools, you’ve got synthesis tools, physical design, custom IC design. There are a lot of engineers involved sharing a lot of information, and there is often no structured processes to actually capture all of that data, so ultimately you will not have a full set of data to actually get good analytics off of.
The second challenge is that it’s not just about the design data and the design results. You’ve got to think about the entire ecosystem, a semiconductor company has product engineering that sets up project schedules, requirements systems and handles issuing defects across entire systems. You have manufacturing teams, so if you’re a fabless company then you have teams that interface with the foundry. An IDM will have their own manufacturing information as well. So to get the true analysis that you need requires a comprehensive view that looks at all this data to be really able to do predictive analysis on the problems that you’re trying to solve.
So the largest problem that we see is that it’s a great goal, but without being able to put the methodology and the systems in place to capture all of that data then it’s going to only be somewhat effective. What we’re focusing on at Dassault is that again through other industries, we’ve been putting processes in place in terms of design process and manufacturing processes that allow us to have a great methodology, and we are capturing all this data now. We’re looking at ways of now bringing this approach to the semiconductor industry, and we’re starting right now through a piece of our technology called requirements-driven verification. This basically will capture the whole design process and verification process.
We can automate the capture of this data now and the very first types of analysis that we’re doing on this data is what we call a Decision Support System. Imagine that you’re doing physical IC design and you’re trying to close timing and your trying to close power, typically you run different experiments and you might run ten or twelve different P&R experiments with different constraint files, making subtle tweaks to the design. You then get a bunch of results out, but it’s often like pushing a balloon if you improve one area another area gets worse, and then you look at the next result while you fix the one that got worse but the one you thought is fixed gets worse now. The minute that you have more than two tests to look at the problem becomes exponentially difficult to try to solve.
In our SIMULIA brand there are some predictive analysis techniques that actually look at multiple groups of tests and analyze what inputs generated what outputs and with what desired results. This can now begin to guide you in a certain direction, so it’ll be able to get all your design constraint files and tell that if you use these design constraints and couple it with other design constraints from this test that you begin to assemble a view that leads you down the right path. We’re looking first at this very specific functional process to begin to make improvements in the overall IC design process to achieve design closure.
The very first step that we’re looking at right now is very much at the role level of providing the analysis capabilities to take the data analysis problem and make it a lot simpler and provide some intelligence at that level.
Q: What is the future of using big data inside of EDA tool flows going to look like?
The obvious next step is to break out from the role level and now look across the entire development platform, and when I mean developing I mean all the way from system design planning through manufacturing. Once you’ve begun to capture enough data you’re able to do different level of analysis, so it moves from looking at how to make my job better to now how do you make the entire system design process better.
If you have a project where you already know what the design results are then you also know who worked in the project, you start to have a notion of how good design teams are, you also start bringing in scheduling information that allows you to make predictions of how design teams work against certain schedules. We can start bringing issues and defects data and see how many errors that certain design teams have made versus other design teams, so you start building a much larger picture for product planning. From design to manufacturing you’re now able to really start predicting schedules at the beginning of a new design. What are my chances of achieving this schedule? Where are the problems going to be?
When you start looking at that data over time we start seeing issues pop up along the way. Well, if I need extra resources now to work on this project, then what teams have done similar projects in the past? Should I apply this engineer to help fix this problem? How is that going to impact my other projects that I have going on where I might start borrowing people from? So it goes from a role based analysis to a system analysis across a whole design team, and then across multiple design teams from a whole company.
Q: On a personal note, I understand that you’re both an engineer and a musician. How did that come about?
It’s a right brain, left brain issue. You know, after spending your days doing pure analysis, analytics and thinking about design problems then everybody needs a creative outlet. Music is one of the best ways to be creative for me. I like to be as creative as possible and let the other side of my brain work. I love it.
Follow the adventures of SemiWiki on LinkedIn HERE!
Related Blogs
Semiconductor market going negative?
The outlook for the semiconductor market for the remainder of 2015 is mixed. Intel’s 3Q 2015 revenues were up 10% from 2Q 2015 and guidance is for 2.3% growth in 4Q 2015. Most other companies which have announced 3Q 2015 results expect revenue declines in 4Q 2015. The most severe drops (based on the midpoint of company guidance) are -16% from NXP and -13% Freescale. NXP is in the process of acquiring Freescale, with the deal expected to close by the end of the year. Some of the weakness in the NXP and Freescale 4Q 2015 outlooks may be due to customers being cautious and waiting to see how the acquisition works out.
[TABLE]
|-
| colspan=”3″ style=”width: 437px; height: 33px” | Key Semiconductor Company Revenue
|-
| colspan=”3″ style=”width: 437px; height: 21px” | Change versus prior quarter in local currency
|-
| style=”width: 221px; height: 21px” |
| style=”width: 107px; height: 21px” | Reported
| style=”width: 107px; height: 21px” | Guidance
|-
| style=”width: 221px; height: 21px” | Company
| style=”width: 107px; height: 21px” | 3Q15
| style=”width: 107px; height: 21px” | 4Q15
|-
| style=”width: 221px; height: 21px” | Intel
| style=”width: 107px; height: 21px” | 10%
| style=”width: 107px; height: 21px” | 2.3%
|-
| style=”width: 221px; height: 21px” | Samsung
| style=”width: 107px; height: 21px” | 14%
| style=”width: 107px; height: 21px” | n/a
|-
| style=”width: 221px; height: 21px” | SK Hynix
| style=”width: 107px; height: 21px” | 6.2%
| style=”width: 107px; height: 21px” | n/a
|-
| style=”width: 221px; height: 21px” | Micron Technology
| style=”width: 107px; height: 21px” | -6.6%
| style=”width: 107px; height: 21px” | -3.5%
|-
| style=”width: 221px; height: 21px” | Texas Instruments
| style=”width: 107px; height: 21px” | 6.1%
| style=”width: 107px; height: 21px” | -6.7%
|-
| style=”width: 221px; height: 21px” | STMicroelectronics
| style=”width: 107px; height: 21px” | -1.0%
| style=”width: 107px; height: 21px” | -6.0%
|-
| style=”width: 221px; height: 21px” | NXP
| style=”width: 107px; height: 21px” | 1.1%
| style=”width: 107px; height: 21px” | -16%
|-
| style=”width: 221px; height: 21px” | Freescale
| style=”width: 107px; height: 21px” | -6.5%
| style=”width: 107px; height: 21px” | -13%
|-
The latest forecasts for 2015 semiconductor market growth range from a 1% decline (VLSI Research and IC Insights) to 1% growth (our latest forecast at Semiconductor Intelligence). The outlook for 2016 ranges from a negative 0.5% from financial services company Credit Suisse to a positive 6.0% from Semiconductor Intelligence (SC IQ).
Earlier in 2015 analysts were more optimistic with several forecasts for semiconductor growth of 7% or higher. Our March 2015 forecast at Semiconductor Intelligence was 8%. As the year developed, it became apparent the global economy and electronics end markets were weaker than expected. The chart below compares forecasts for 2015 and 2016 from Gartner released in March 2015 and September 2015 for PCs + tablets and for mobile phones. The most significant change was 2015 PC + tablet shipments dropping from 0.4% growth in March to a 9.3% decline in September. The 2015 mobile phone forecast dropped from 3.5% in March to 1.4% in September. 2016 forecasts changed less, with PCs + tablets dropping from 6% to 1.8% and mobile phones dropping from 3.8% to 2.9%.
The 2015 global GDP forecast from the International Monetary Fund (IMF) also dropped in the last six months from 3.5% in April to 3.1% in October. The 2016 forecast dropped moderately, from 3.8% to 3.6%. Our semiconductor market forecast at Semiconductor Intelligence went from 2015 growth of 8% in March to 1% in September. Our 2016 forecast has decreased only slightly, from 7% in March to 6% in October.
Why is the change in 2016 forecasts not as significant as the change in 2015 forecasts? A skeptic might say analysts do not alter their forecasts until actual data begins to prove them wrong. We are not quite that cynical. The IMF forecast for 2015 dropped from 3.5% to 3.1% primarily due to slower than expected growth in the U.S., a deeper than expected downturn in South America, slower growth in the Middle East because of falling oil prices, and growth slightly below expectations in India and Southeast Asia. Despite all the concern in the media about slowing growth in China, the IMF’s October forecast for 6.8% growth in 2015 and 6.3% growth in 2016 are unchanged from the April forecast. Conditions still point to GDP growth acceleration in 2016. Despite slower growth in China, the advanced economies (including the U.S., Europe and Japan) should improve in 2016. Russia and South America are expected to begin to recover from 2015 recessions. India and Southeast Asia GDP growth should accelerate in 2016.
We at Semiconductor Intelligence feel confident about reasonable growth in the semiconductor market in 2016. Although there are some areas of concern in the global economy, signs point to better conditions in 2016. The key end markets for semiconductors (PCs, tablets and mobile phones) are also expected to improve in 2016.
Is This a Dagger Which I See Before Me?
Macbeth may have been uncertain of what he saw but, until recently, image recognition systems would have fared even less well. The energy and innovation put into increasingly complex algorithms always seemed to fall short of what any animal (including us humans) is able to do without effort. Machine vision algorithms have especially struggled to be robust to distortions, different lighting conditions, different poses, partially obscured images, low quality images, shifts and many more factors. Macbeth’s dagger might have been recognized face-on in ideal lighting but probably not in this troubled vision.
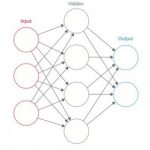
The problem seems to have been in the approach, a sort of brute-force attempt to algorithm our way to recognition. A different research path asked if we could model recognition on how we see and especially how the visual cortex maps images to recognized objects. First the image is broken up into small regions. Pixels within each region are tested against a function to detect a particular feature such as a diagonal edge. The function is simple – a weighted sum of the inputs, checked against a threshold function to determine if the output should trigger. Then a second feature test, now for a different feature (perhaps color), is applied again across each region in the image. This process repeats across multiple feature tests, as many as 100 or more.
All of these outputs are fed into a second layer of neurons. The same process repeats, this time with a different set of functions which extract slightly higher level details from the first-level. This then continues through multiple layers until the final outputs provide a high-level characterization of the recognized object. Implement that in a compute engine of some kind and you have a Convolutional Neural Network (CNN). What the CNN is good at recognizing is determined by the weights used in each feature test; these are not set by hand but rather by training the CNN over samples images. Which is as it should be since this is mimicking functions of the brain.
CNNs were something of a backwater in vision research until 2012 when a CNN-based solution beat all comers in a widely-respected image recognition challenge. Since then almost all competitive work in this area has switched to CNNs. These are now achieving correct detection rates (CDRs) in the high ninety percent range, besting not only other solutions but also human recognition in some cases, such as identifying species of dogs and birds.
Cadence has implemented a CNN on the Tensilica Vision P5 DSP. They used as their reference a test known as the German Traffic Sign Reference Benchmark, a small sample of which is shown here. This should give you some sense of the recognition challenge: low lighting, glare, dappled lighting, signs at angles, signs barely in focus – these are fully up to the limits of our own ability to recognize. Cadence was able to achieve CDRs of over 99%, and nearly 99.6% with a proprietary algorithm which beats all known results to date. They have also demonstrated with this algorithm the ability to trade-off a small compromise in accuracy for greatly reduced run-times.
The Tensilica Vision P5 DSP is pretty much ideal for building CNNs. As a DSP, multiply-accumulate instructions (for all those weighted sum calculations) are native. It supports high levels of parallelism through a VLIW architecture and ability to load long words from memory every cycle, so multiple image regions can be processed in parallel. And it has many other features which support the special functionality required by CNNs. All this is good but the results ultimately testify to the strength of the solution. Running the Cadence algorithm, this approach is able to identify 850 traffic signs per second. For pedestrian and obstacle recognition, and as we progress towards greater autonomy in cars, that kind of quick reaction time is critical.
No complete vision system will be implemented solely with a CNN. A complete system must first identify areas in the image to which recognition should be applied, then recognize and finally provide guidance based on what has been recognized. This requires an architecture adept across wide range of functions, supporting a rich set of operations, multiple data-types, and should be balanced to support traditional vision algorithms as well as CNNs, demands for which the Vision P5 solution is well suited.
I find it interesting that Cadence is investing heavily in the software part of this solution. Rather than run benchmarks based on open-source software, they’ve built their own software and have gone deep enough to produce a best-in-class CNN algorithm. Where they take this next should be interesting to watch. To learn more about the Tensilica Vision P5 DSP and the Cadence CNN algorithm, clickHERE.
If Macbeth had access to this technology, events might have taken a different though less poetic and certainly less dramatic turn:
Is this a dagger which I see before me? Let’s check this gizmo. No – definitely not a dagger. Well, can’t argue with technology. I’ll just have to tell the wife it’s off. I’m not going to kill the king.
Diversity of chip segments had tempered downturns but no more?
* The Current Downturn is more Broadly Based…
* Back to the “bad old days” of Lemmings off a cliff???
* Its not just a Foundry thing…
* All corners of the chip industry are impacted!!!
Continue reading “Diversity of chip segments had tempered downturns but no more?”
New CoreLink IP ties in mobile GPU coherently
A mobile GPU is an expensive piece of SoC real estate in terms of footprint and power consumption, but critical to meeting user experience demands. GPU IP tuned for OpenGL ES is now a staple in high performance mobile devices, rendering polygons with shading and texture compression at impressive speeds.
Creative minds in the desktop space long ago figured out that GPUs can be viewed as vector engines, and can be put to work on accelerating computational tasks general purpose CPUs grapple with. This was an ideal use case for mobile space, with tasks like facial recognition, computational photography, and embedded vision growing in popularity.
There are a few problems, however. First is the programming model; CPUs and GPUs are radically different. To try to solve that, Apple and others got their arms around OpenCL, providing parallel constructs with the hope of getting heterogeneous processing units to work together. OpenCL made significant progress for many tasks.
The second problem is memory space – CPUs have theirs, GPUs have theirs, and betwixt is a performance problem usually solved by copying data between the two spaces. AMD and others brought HSA (Heterogeneous System Architecture) to the table, redefining the interface between CPU and GPU (or other execution units) around a shared memory space.
Which brings us to the third problem. Shared memory is fantastic, but real performance in a multicore CPU architecture means lots of cache, and with it cache coherence. Cache miss penalties can be brutal – especially on large files like images. Tossing GPUs into the processing mix without cache coherence may produce gains on very particular benchmarks. For greater gains and consistent performance, we need new IP that maintains coherence.
ARM has rethought their interconnect architecture, introducing two new IP blocks to bring in a new crop of fully coherent GPUs. We should mention here that ARM has a three-tiered product strategy for interconnect: a low-end CoreLink NIC for basic SoCs, a high-end CoreLink CCN for the AMBA 5 CHI server-class multicore crowd, and the mid-range where this announcement lives.
The new CoreLink CCI-550 is shown with six ACE interfaces, two for a big.LITTLE cluster, and four for the GPU. This is the scaled-up configuration offering up to 60% peak interconnect bandwidth compared to the CCI-500. The CCI-550 also scales down with fewer ACE and memory interfaces for more optimized solutions. The key feature of the CCI-550 is the integrated snoop filter, which foregoes the need to send all snoops to all processors, instead using one central snoop. This lowers snoop latency and relieves what would otherwise be quadratic scaling, and removes speculative DRAM accesses.
Those DRAM accesses come through a new DRAM controller, the CoreLink DMC-500. Tuned for up to LPDDR4-4267, the DMC-500 ups memory bandwidth by 27% and drops CPU latency by 25%. These solutions have been qualified to work together, reducing integration issues.
There is also some intrigue over the GPU itself in this diagram. During our pre-briefing, ARM declined to provide details on the Mali “Mimir” GPU other than confirming new IP is in the works. My guess is stay tuned, details to be announced at ARM TechCon coming up in a few weeks. I also asked if other GPU vendors are working on coherent IP; ARM said only that they are currently sharing information under the auspices of the HSA.
Full press release for this announcement:
New ARM CoreLink System IP Provides the Foundation for Next-Generation Heterogeneous SoCs
Fully coherent ARM CPU/GPU combinations could get interesting, although the chances of something like the Quake-Catcher Network emerging on distributed mobile devices have an expensive metered 4G pipe sitting in the way. Still, removing the barrier of coherence for mobile SoCs means new algorithms taking full advantage of GPU compute power are up for grabs. This could also introduce an interesting dynamic for HSA and alternative CPU and GPU core solutions, beyond just an ARM offering.
My View of Contextual Leadership
Go off and do something wonderful,” said Robert (Bob) Noyce, co-founder of Fairchild semiconductors and Intel Corporation. He was heard, and the quality of our lives has been elevated by the wonderful pursuits of skilled pioneers. Notice that Bob did not say, “Go off and become great leaders.” This is because great leaders of the past did not set out to be that. They set out to do wonderful things.
Bob and others became known as great leaders by those who were awed by their achievements. Many of us studied their lives in order to extract recipes of leadership. With such recipes, we try to cook ourselves into leaders. But we don’t need to cook ourselves into anything. We just need to focus our attention on cooking a finger-licking good meal alongside other cooks in the kitchen. We will do well to get rid of our fascination with how to become a good leader. That is not the goal.
Defining our career aspiration
Bob is fondly and justifiably remembered as the mayor of Silicon Valley. Back in the 1980s, I was fortunate enough to witness Bob pondering alone or talking to people in the backyard of Intel’s Santa Clara building 9, which is in the same campus on which we later built a monument in his memory and called it the Robert Noyce building. I was too young then to have had a meaningful conversation with him personally. The closest I came to interacting with him was a few pleasant exchanges, one of which involved helping him light his cigarette on a windy day.
I wonder how Bob would have defined “wonderful.” I think he would have said that a wonderful thing is an impactful result beneficial to humanity. And after we have done a wonderful thing, I imagine he would advise us to do the next wonderful thing and to never stop.
In line with this thinking, I have harbored a career aspiration of increasingly impactful results that are beneficial to humanity and are achieved through methods which generate goodwill with people. I believe this is a pretty good definition of effectiveness as it encompasses results, positive impact and goodwill – all crucial components of effectiveness.
At its core, effectiveness is made of three basic elements: Crave, Act, and Care. Craving drives passion for impact and the courage to pursue it. Action applies the sweat and discipline necessary to achieve the desired impact. Care helps us achieve it in a way that generates good will.
By the time we enter the workforce, we either have these three basic elements of effectiveness or we don’t. I don’t know of a way to teach an adult how to crave, act, and care.
I do think it is possible to optimize the balance of these elements when they exist in varying degrees, however. When you see the right balance in a person, you are witness to a powerful force fueling a limitless spiral of effective contributions from that person.
When you next meet with yourself, ask yourself these three questions: Do I crave? Do I act? Do I care? If the answer to these questions is an honest yes, go off and do something wonderful! And never stop. Humanity will thank you for it.
Enabling behaviors of effectiveness
Beyond the three elements of effectiveness, lie three key essential behaviors which can each be learned and honed through practice. These are to Lead, Follow, and Collaborate. Leading is the act of pointing to a wonderful thing, initiating the journey to it and directing/guiding along the way.
Following is to understand what is being pointed to and to do our part under guidance on the journey to it. Part of following is to lead the leader with one’s questions and vigilance.
Collaborating is the act of co-envisioning and co-creating a wonderful thing. Collaborating melds leading and following together into a beautiful dance. The dance fully leverages the motivations, knowledge and experience of participants as they hand the baton of leading to each other in real time.
Contextual leadership
Contextual leadership is knowing when and how to lead, follow and collaborate. What we do and when we do it is based on contexts at various levels.
The first, and the most important context, is the individual context. For each involved individual, this context includes the attributes of functional role, mandate, capability and career motivation for that individual. These attributes taken together and applied to the topic on hand determine the placement of leading or following batons in their hands for that particular topic. This does not imply that an individual’s behavior is constrained by these attributes. The attributes’ impact can be managed and the attributes themselves change, but it is important to understand the attributes to set the level of empowerment an individual exercises in any situation. Additionally, it is not only important for us to know our own context, but also that of our colleagues. And for that, curiosity and strategic disclosure in a trust-cushioned environment is essential.
Next is the topical context. The topic in a discussion, the problem being solved, or the new paradigm under creation demand very specific contributions for their own success. The intersection of this context with the individual context, when understood well by all involved leads to gliding ease with which an individual takes and gives the leading and following batons.
Finally, the environmental context. The attributes of this context include trends, constraints and opportunities in the socio-political, enterprise and market environments. A good understanding of this context shines the right light on the topical context to determine not only the nature and timing of wonderful pursuits. We need to know when to follow hard constraints and when to lead and collaborate on opportunities to bust current paradigms.
Wonderful results, in my experience, show up when creators crave, act and care. When they crave, act, and care they gracefully take turns leading, following, and collaborating as directed by context.
Happy pursuits!
Sunit Rikhi
www.ReachforInfinity.com
Delivering Zero Defect Products – EVS Testing
Competition in the semiconductor product marketplace has grown increasingly difficult as suppliers constantly search for ways to differentiate their products. Customers expect low cost, problem-free product performance. Automotive manufacturers in particular expect zero defects as field failures can prove very costly.
Since no manufacturer is currently capable of producing zero defect products, this goal would seem unrealistic. However, the customer expects zero defects in the products they receive, not necessarily in the products as produced. This suggests that while defect reduction remains important, effective screening of latent defects is paramount.
Elevated voltage stress, or EVS testing provides a cost effective approach to screen out defects. Burn-In testing is used by some manufacturers to detect and remove latent defects that pass undetected through standard electrical test methods employed at the Supplier’s Wafer Sort and Final Test operations. However, Burn-In testing is extremely expensive and lasts days if not weeks to complete.
Many latent defects act to thin dielectric isolation between two conductors in the semiconductor device, such as in the gate oxide or intermetal dielectric. Since dielectric strength of these films is well understood, EVS testing can be used to detect and screen these defects to ensure surviving units last as long as needed in field use.
Consider the figure above. Two types of defect populations are plotted in weibull format. Population type 1 maintains straight line behavior from the first failure to the last with all defects occurring due to device wearout. These defects are not consequential since wearout occurs well beyond the useful life of the product. Population type 2, on the other hand, has multiple slopes with many extrinsic defects. These defects are cause for concern. The defects located in zone A fail at low charge levels and are likely removed during standard wafer sort or final testing at the component supplier. Those defects shown in zone B, conversely, would likely survive internal testing and possibly fail in field use as the cumulative charge (Q) increases.
To screen zone B latent defects, EVS testing can prove effective. The governing equation illustrating the role of EVS testing appears below.
In this example, the standard test voltage used at Wafer Sort is 5.2v and the EVS test voltage is 10 volts. As indicated, if a 3 sec EVS test is applied, the corresponding field lifetime is 189,467 years! Of course, testing at such an elevated voltage may not always be possible since other circuit devices may be damaged but the potential benefits of EVS testing is clear. Lower voltages and/or lesser test times can be employed to achieve the desired effect with more reasonable test times.
Follow the adventures of SemiWiki on LinkedIn HERE!