Waze’s Connected Citizens program continues to get a lot of positive attention for its partnerships with cities and states around the world. The program provides free access to Waze traffic and crowd-sourced data in exchange for information about road closures and traffic incidents.
Continue reading “Waze Stealing the Keys to Your City!”

Google’s New Nexus 5X Features One Major Overlooked Wireless Upgrade
In the world of smartphones there is a never ending list of specifications that are constantly considered by consumers when buying them. No line of phones is more scrutinized for its specs than the Google Nexus line of smartphones. This is primarily because the people looking to buy Nexus phones are already Android enthusiasts and want to have the best possible Android experience thanks to the direct update support from Google and ‘vanilla’ experience.
MU-MIMO WiFi throughput improvements on the Nexus 5x are substantial
However, in the past this has been accompanied by hardware that isn’t always the latest or the fastest. Google has blown through that past with the latest line of Nexus phones in the Nexus 5X and 6P. The Nexus 5X and 6P are replacements for the Nexus 5 and Nexus 6 which is the first time Google has released two new Nexus phones at the same time. One of the most overlooked upgrades to the new Nexus line of phones lies beneath their wireless connectivity and how much that new hardware enables a better experience and faster performance.
For comparison’s purposes I will be comparing the Nexus 5X against the Nexus 5 since I already have a Nexus 5 and don’t have a Nexus 6, I shied away from the Nexus 6 due to the phone’s enormity. The new Nexus 5X sells for a paltry $329 for the 16GB model, which is currently $50 off during the holidays. It features a Qualcomm Snapdragon 808 SoC, 5.2” 1080P LCD with Gorilla Glass 3, 12.3-megapixel main camera with f/2.0 aperture and 4K video recording and 2GB of RAM. All of this is powered by a 2700 mAh battery which is designed to give the phone a long battery life.
It also features three very forward looking technologies that are quickly becoming industry standards. The fingerprint sensor is one of the things that is quickly becoming an industry standard feature as it is already found in Apple’s and Samsung’s latest smartphones. The inclusion of a USB Type-C connector is also extremely forward thinking of Google considering how few phones currently utilize the standard which is going to eventually become the standard for most USB connectivity. Last, but certainly not least, is the addition of new connectivity that enables LTE Cat 6 carrier aggregation and 802.11AC multi-user MIMO Wi-Fi. I’ve extensively written about multi-user MIMO, also known as MU-MIMO, and even written a paper about its eventual expansion as an industry standard feature. That was with phones from Xiaomi in China, a leading smartphone technology innovator, but now Google’s Nexus phones also have it, giving the technology even more relevance than before to the U.S. and Western Europe.
The new Nexus 5X makes a huge leap over the Nexus 5 and even the Nexus 6 in terms of Wi-Fi capability with not only the addition of MU-MIMO support, but also by featuring a 2×2 Wi-Fi antenna which significantly improves the Wi-Fi signal as well as the performance. By making these two major upgrades to the Wi-Fi connectivity of the phone, Google is showing the importance that they are putting on Wi-Fi as well as how much they believe a good Wi-Fi experience is important to the smartphone user. This is partly due to Wi-Fi’s growing relevance and how much carriers are trying to push users to use Wi-Fi when possible to improve their experience, the best example being the implementation of Wi-Fi calling with nearly all of the US mobile operators.
In order to really see how much Google has improved the Nexus 5X over the Nexus 5 Wi-Fi performance I asked Anshel Sag, Moor Insights & Strategy technical writer and technologist, to take a look at the two phones side by side in terms of performance while using a Linksys MU-MIMO capable router, the EA8500. Most high-end consumer routers nowadays feature 802.11ac MU-MIMO Wi-Fi capabilities which enable significantly better utilization of the router’s speed as well as overall better performance per device. But before testing multi-user MIMO capabilities, we just wanted to look at the performance difference between the Nexus 5X and Nexus 5 over Wi-Fi assuming that you don’t have an MU-MIMO capable router.
The SU or single-user testing, done using TCP, found that the Nexus 5X came in at a blazing 305 Mbps while the Nexus 5 only came in at 170 Mbps. We also tested with the Xiaomi Mi Note Pro, which we had used in our original testing of MU-MIMO capable smartphones and router and that phone sat in the middle with a download speed of 246 Mbps. Looking at two devices being used simultaneously, when the Nexus 5X was used along with a Xiaomi Mi Note Pro, the aggregate download bandwidth was 340 Mbps, this is compared to the Nexus 5 with the exact same Mi Note Pro only delivering 243 Mbps, almost 100 Mbps overall slower. In testing three devices, the fastest configuration unsurprisingly included two Xiaomi Mi Note Pros and the Nexus 5X, with an aggregate download bandwidth of 306 Mbps while the Nexus 5 with the same configuration only saw a total of 255 Mbps.
Upon switching on the MU-MIMO functionality inside of the router, we saw a pretty nice boost to the performance when multiple devices are using the network, which is expected considering that is MU-MIMO’s primary function. In fact, even in a single device configuration the Nexus 5X saw a nearly 10% performance boost at 332 Mbps with MU-MIMO turned on.
Moving on to a two device configuration, we were able to test the Nexus 5X with the Xiaomi Mi Note Pro and got an aggregate bandwidth of 381 Mbps, which is vastly better than the 237 Mbps that the Nexus 5 was able to deliver in the same configuration with a Mi Note Pro. This represents a massive bandwidth difference of nearly 150 Mbps, which is an additional 50 Mbps on top of what we saw in the single-user testing. Last but not least was the much awaited three device configuration, where we saw the Nexus 5X with two Xiaomi Mi Note Pro phones deliver download bandwidth of 408 Mbps. The Nexus 5, with the same Mi Note Pros was only capable of 300 Mbps of total bandwidth, which is a solid 100 Mbps slower than the same configuration with the 5X. What’s even more interesting is that thanks to MU-MIMO, even the Nexus 5 actually saw a slight performance bump jumping from 92 Mbps with the router in SU mode to 112 Mbps in MU-MIMO mode.
What this ultimately boils down to is that Google has made an extremely wise decision in their implementation of a 2×2 802.11ac Wi-Fi configuration with MU-MIMO. This technology gives the Nexus 5X some of the best Wi-Fi performance among most phones we’ve seen to this date and the best performance when multiple devices are being used on the network at the same time, especially with an MU-MIMO capable router. The overall performance uplift is as much as 30% as represented by our tests when going from single-user to multi-user MIMO and that combined with the improved signal and overall faster bandwidth makes Google’s decision almost a no brainer. Given WiFi is the preferred method of smartphone usage, I cannot wait to see this feature from other manufacturers like Apple, Samsung, but for now, Google’s Nexus 5X and 6P have the Wi-Fi advantage.
More from Moor Insights and Strategy
OCF shows there may be hope for IoT consortia yet
The recent launch of the Open Connectivity Foundation (OCF) was met first with a wave of “oh good, another IoT consortium”, then “phew, it’s just a rebrand of the OIC”, followed by a bit of confusion over why a few AllSeen Alliance players and some other names jumped in. Is it just a marketing ploy, or is there more to this? Continue reading “OCF shows there may be hope for IoT consortia yet”
The Age of Automotive Electronics
One of Intel’s most advanced fabrication sites is called Ronler Acres, located in Hillsboro, Oregon and I jumped at the opportunity to visit this site on April 26th when members from the SEMI Pacific Northwest Chapter are meeting to discuss a timely topic, “The Age of Automotive Electronics”. The previous SEMI event that I attended was back in October 2015 when the topic was, “The Future of Moore’s Law“. Because of the number of speakers the April event will start out with a breakfast at 7:30AM and continue until 11:30AM.
Our society in America is certainly auto-centric and the trends toward increasing sophistication and automation in our driving experience continues at a fast rate. Just stop and think about all of the changes taking place in the automotive world today:
- Electric Vehicles, from Chevy Volt up to the Tesla
- Autonomous Cars, from companies like: Google, VW, BMW, etc.
- ADAS (Advanced Driver Assist)
- Infotainment
- Connected cars
- Embedded software to control all of the electronics
- Smart Streets
- Smart Lights
Source: The Clemson University Vehicular Electronics Laboratory
Attend this event and you’ll get to hear from industry speakers that work at:
- Intel – the largest employer in Oregon and leading semiconductor company
- Mentor Graphics – the largest EDA company in Oregon
- Gartner – a research and advisory firm
- Drive Oregon – innovation in electric mobility
The first three companies I have heard about before, and even worked at the first two. Although I live in Oregon I hadn’t really heard about Drive Oregon until learning about this SEMI event, so I visited their web site and found this informative 2:45 minute overview video:
Plan to bring along some business cards to hand out while you network with other technology professionals and meet local industry executives.
Registration
You may register online here. Get an early bird rate before April 13th.
Related Blogs
Healthcare Predictive Analytics Insights from Patents
Predictive analytics analyzes current and historical data to make predictions about future events and trends. The predictions are based on the predictive models that are generated from a machine learning technique that recognizes pattern in the current and historical data.
US20140275807 illustrates the predictive analytics application in the personalized medicine. Personalized medicine refers to the use of a diagnostic to target a therapy at a patient exploiting the patient’s individual health data including genotypic that are most likely to benefit from the therapy. Diagnostics is the first step in defining the precise nature of a patient’s disease state. Alzheimer’s disease diagnosis is complex, particularly in the early stages of disease. Alzheimer’s disease is caused by disorders of the brain and central nervous system. The predictive analytics can predict a response of the patient to a particular therapy. Thus, by analyzing the integrated diagnostic data of the patient, the predictive analytics can predict Alzheimer’s disease at a pre-symptomatic stage.
US2016001935 illustrates a system for monitoring a healthcare provider’s operation and performance, and thus, providing tools to make better business decisions, reduce costs, and improve operating efficiency using the predictive analytics. The system receives data associated with the healthcare provider’s operation and performance. The predictive analytics models determine forecast and predict future trends utilizing the aggregated data. Especially, the predictive analytics combines clinical, supply chain and claims data to allow a healthcare provider to compare and contrast how changes in choice of medical devices, medicines, etc. impact both clinical outcomes and profits by physicians, specialties, and payers.
US20150310179 illustrates the software as a service (SaaS) platform for providing analysis of large database regarding patients’ diagnosis and treatment information. The predictive analytics defines decision points that are relevant to clinical decision-making by generating optimal probabilities and likelihood ratios through analysis of information contained in the database.
US20120165617 illustrates a system for early health and preventive care using data from wearable sensors. Data collected from the sensors is transmitted to a mobile cloud computing platform-as-a-service (PaaS). The predictive analytics analyzes the received data to predict diseases and other conditions to which the patient may be predisposed.
Five Reasons to be More Bullish on a 2016 Commercial PC Refresh
Last week’s IDC and Gartner Q4-2015 report on PC sales sent a shock-wave through the industry. The stock market responded with a sell-off of major PC-related names like Advanced Micro Devices, HP Inc. (fka Hewlett-Packard), Intel, Lenovo, and NVIDIA. While I was disappointed in the Q4 numbers, I also have a good grasp of what was behind the numbers, what is standing in the way of better sales, and what’s being done to overcome the challenge. What I’d like to talk about here are a few reasons why I think 2016 could be a good year for commercial PCs, barring a global GDP meltdown. I want to focus on a few workplace trends, specifically around millennials. I do a deep dive in a paper here if you want more details.
Millennials are unlike other generations
The key to what I think could be a key driver of a 2016 commercial PC refresh are millennials– you know, those “kids” born after 1980 and adults at the turn of the millennium. Well, those “kids” are now a major part of the workforce and based on Moor Insights & Strategy estimates, account for 30-40% of IT decisions or purchase influences. That millennial generation grew up with PCs in elementary school, GUIs (graphical user interfaces) in middle school, cellphones in high school, and probably a smartphone in college. Today, they cling to their thin and light smartphones (as I do), own a PC and probably a tablet. Expectations of electronics responsiveness, battery life, industrial design, and battery life expectations are dictated by their smartphones.
Credit: (flickr ITU Pictures)
IT still providing Windows 7 clunkers to users
Most of the installed base of commercial PCs are Windows 7-based systems, three to five years old, are slow, thick and clunky. These aren’t systems that you want to open up around your friends. This is one of the biggest drivers of why BYOD PCs came about. IT’-provided PCs stunk. I think the industry talked a good game about what it wanted to do in IT with all those svelte commercial notebooks, but there were a few issues that stood in the way. Most of enterprise IT weren’t prepared to extensively roll-out the thin and light variants because on the whole, they were consumer converted notebooks that looked more like a MacBook than a commercial PC. Also, IT didn’t buy into the “give me a good PC or I won’t work here” attitude and kept issuing clunkers.
Millennials don’t want to work with clunkers
Well, millennials kept bringing in their consumer laptops and found ways to get work done with a “nice” consumer PC in spite of IT. Millennials have had enough and today, our research suggest that they now have bargaining power in that they don’t want to and won’t work for companies that offer clunky technology. Every shred of research I have done, seen from OEMs and the rest of the industry leads me in this direction. Some IT groups gets it, many don’t and are ironically driven by executive staff and HR to step it up and do something different.
New commercial PCs announced at CES very different
The great news is that from what I saw at CES, for the first time, commercial PCs can be as sexy, cool, responsive, with long battery life as the latest, cutting edge consumer PC and even a smartphone, but with the reliability, durability, service of a managed, commercial PC. These are systems primarily from Dell (Latitude), HP Inc. (EliteBook), and Lenovo (ThinkPad) and in my opinion, can provide enterprise users with the best of both worlds. Intel’s 6th generation processor, code-named SkyLake, is at the heart of most all of these systems, and when you compare Intel SkyLake-based PCs from the last 5 years, there’s literally no comparison.
Intel’s SkyLake processor enables these new devices
Intel’s Skylake processors bring not only integration with Microsoft Windows 10, but also performance improvements in Windows 7 and 8.1 over chips from 5 years ago, the average age of currently installed PCs. Skylake delivers about 25% more performance over Sandy Bridge while also reducing power. GPU performance on current generation Intel integrated graphics is in many cases over 500% better than previous generations of Intel graphics over the course of the 5-year average PC age. The improved graphical performance is partly what has enabled the higher resolutions mentioned earlier.
More importantly, when you look at the new levels of style, battery life, and the new responsiveness, it brings the PC much closer to the expectation of a smartphone. While the PC industry doesn’t like to make comparisons to the smartphone, that’s the expectation reality. That’s the bar. From my point of view, the good news is that the commercial PC industryfinally has that platform that brings the best of consumer with commercial and that’s Intel’s SkyLake. This is one reason why I’m bullish on the 2016 commercial PC refresh.
One big caveat here. If GDP tanks, all bets are off. There is a direct relationship between commercial PCs and GDP so if it gets any worse, it probably won’t be a good year. I’ll hit on some of the other commercial PC drivers in future columns. If you are looking for more details on this, you can find a short paper here.
Solving the Next Big SoC Challenges with FPGA Prototyping
The health of the semiconductor industry revolves around the “start”. Chip design starts translate to wafer starts, and both support customer design wins and product shipments. Roadmaps develop for expanding product offerings, and capital expenditures flow in to add capacity enabling more chip designs and wafer starts. If all goes according to plan, this cycle continues.
Unfortunately “all” rarely goes according to plan especially if you are in a competitive market and designing on leading edge processes. This is where FPGA-based prototyping comes in. A complete verification effort has traceable tests for all individual intellectual property (IP) blocks and the fully integrated design running actual software (co-verification) and is far beyond what simulation tools alone can do in reasonable time. Hardware emulation tools are capable and fast, but highly expensive, often out of reach for small design teams. FPGA-based prototyping tools are scalable, cost-effective, offer improved debug visibility, and are well suited for software co-verification and rapid turnaround of design changes.
Which brings us to this week’s tutorial at DVCON. I hope to see you there:
Solving the Next Big SoC Challenges with FPGA Prototyping and Stratix 10
We’re all too familiar with the fact that large SoC designs present challenges in both design and verification. FPGA prototyping offers obvious advantages for both design and verification but many dismiss the notion of employing FPGA prototyping because of size constraints, hardware scalability, partitioning challenges, performance, debug ability, and in-circuit testing. While previous generations of FPGAs and FPGA prototyping couldn’t tackle large designs, advances in both FPGA and FPGA prototyping technologies and methodologies have given way to breaking through these challenges.
This tutorial will explore the advances of Altera’s Stratix 10 FPGA and the FPGA prototyping techniques and technology that will work with Stratix 10 to accomplish the prototyping of even the largest SoC. Case studies will be provided that will demonstrate how to properly take advantage of Stratix 10 FPGA prototyping for compiling, partitioning, and debugging across multiple devices.
THURSDAY March 03, 2:00pm – 5:30pm | Sierra
Speakers:
Toshio Nakama – S2C, Inc.
Manish Deo – Intel/Altera Corp.
If you get the chance to meet Toshio after the tutorial I would highly recommend it. He is the Co-founder and CEO of S2C, Inc. and has over 18 years of experience in the electronic design automation industry as well as FPGA architecture and design. Prior to S2C, Toshio held the positions of Asia director of sales and field applications engineering manager at Aptix and worked at Altera. Toshio has an EMBA degree from CEIBS and a BSEE from Cornell University.
DVCon is the premier conference for discussion of the functional design and verification of electronic systems. DVCon is sponsored by Accellera Systems Initiative, an independent, not-for-profit organization dedicated to creating design and verification standards required by systems, semiconductor, intellectual property (IP) and electronic design automation (EDA) companies. In response to global interest, in addition to DVCon U.S., Accellera also sponsorsDVCon Europe andDVCon India. For more information about Accellera, please visitwww.accellera.org. For more information about DVCon U.S., please visitwww.dvcon.org. Follow DVCon on Facebookhttps://www.facebook.com/DVCon or @dvcon_us on Twitter or to comment, please use #dvcon_us.
Enterprise SSD SOC’s Call for a Different Interconnect Approach
The move to SSD storage for enterprise use brings with it the need for difficult to design enterprise capable SSD controller SOC’s. The benefits of SSD in hyperscale data centers are clear. SSD’s offer higher reliability due to the elimination of moving parts. They have a smaller foot print, use less power and offer much better performance. SSD’s are also more scalable, a big plus where storage needs run into the petabyte range.
Nevertheless, SSD’s create the need for more complex and sophisticated controllers. Unlike early SSD implementations that used SATA, SAS or Fibre Channel to connect to their hosts, enterprise SSD use NVMe protocol to directly connect to PCIe. NVMe was developed specifically for SSD memory and takes advantage of its low latency, high speed and parallelism. The table below from Wikipedia shows the comparison.
Enterprise SSD controllers connect to many banks of NAND memory and deal with low level operations such as wear leveling and error correction, both of which have special requirements in this application. The SSD controller must offer low latency, extremely high bandwidth, low power, and internal and external error correction.
A large number of unique IP blocks must be integrated to deliver a competitive SSD controller SOC. Here is a short list of necessary IP’s that are commonly used: ARM R5/7, PCIe, DDR3/4, NVMe, DMA, RAM, SRAM, RAID, NAND, GPIO, ECC and others. The parallel operation of these IP blocks presents a significant design problem for IP interconnection and internal data movement.
Designing the interconnections between all the functional units has become one of the most critical aspects of these designs. Due to larger IP blocks with wide buses and increasing need for interconnect using wires that are not scaling with transistor sizes, the design effort and chip resources consumed by on-chip interconnections are becoming a large burden to design teams.
Buses and crossbars are running out of steam in these newer designs. For example, going to AMBA 4 AXI for 64 bits requires a width of 272 wires, and 408 wires for 128 bits of data. The other problem is that many of these wires are idle for much of the time. For example, a four cycle burst write transaction only uses the 56 wire write address bus in 25% of the cycles.
Networks on Chips (NoC) dramatically reduce the difficulties that would be encountered with large bus structures. Arteris, a leading provider of NoC IP, has just published a white paper on the advantages of using their FlexNoC to facilitate implementation of enterprise SSD controllers. The biggest advantages come from simultaneously reducing the widths of the block interconnections and tailoring them to the predicted traffic. It’s well understood that the earlier in the design process issues are addressed the easier it will be to deal with the downstream effects of that issue. Instead of waiting for the P&R stage to grapple with interconnect across the chip, FlexNoC planning and implementation starts at RTL, making the process more efficient and easier.
FlexNoC works by converting a wide variety of IP protocols at their source to agnostic serialized packet data and routing it to its target, where is it reassembled upon delivery. There are RTL elements required for the NoC to operate but the overall area required by the NoC IP and interconnect wires is significantly less than the equivalent bus or crossbar structures. Because the NoC data can be pipelined and buffered, it is actually faster than high drive strength busses. The NoC RTL can be synthesized and placed so that it conforms to the predefined routing channels.
The overall effect is less routing congestion, leading to a smoother back end implementation flow. The resulting design benefits from less latency and even more robust data integrity due to built in error correction within FlexNoC.
To gain a deeper understanding of the benefits of using FlexNoC I suggest reviewing the Arteris white paper located here. There are a number of additional benefits and implementation details that are covered in this and the other available Arteris downloads
Multi-Level Debugging Made Easy for SoC Development
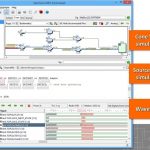
An SoC can have a collection of multiple blocks and IPs from different sources integrated together along with several other analog and digital components within a native environment. The IPs can be at different levels of abstractions; their RTL descriptions can be in different languages such as Verilog, VHDL, or SystemVerilog.
Continue reading “Multi-Level Debugging Made Easy for SoC Development”
FPGA tools for more predictive needs in critical

“Find bugs earlier.” Every software developer has heard that mantra. In many ways, SoC and FPGA design has become very similar to software development – but in a few crucial ways, it is very different. Those differences raise a new question we should be asking about uncovering defects: earlier than when? Continue reading “FPGA tools for more predictive needs in critical”