What if you could reduce power and extend chip lifetime, without compromising performance? We all know the importance of power optimization for advanced SoCs. Thanks to the massive build out of AI workloads, power consumption has gone from a cost or cooling headache to an existential threat to the planet, if current power consumptions can’t be managed. Against this backdrop proteanTecs recently held an informative webinar on the topic of power and performance optimization.
The discussion goes beyond adaptive techniques, better design strategies and enhanced technology. A method of performing per-chip, real-time optimization is described and the impact on power consumption and device reliability is dramatic. A replay link is coming but first let’s explore an overview of the proteanTecs webinar – “Power is the New Performance: Scaling Power & Performance for Next Generation SoCs”.
What Was Discussed
Noam Brousard, vice president of solutions engineering at proteanTecs, begins the webinar with a summary of industry best practices and the compromises they represent. He explains that applying a Vmin to all chips has significant drawbacks. Thanks to effects such as different process variation, usage intensity, system quality and operational conditions, a single Vmin will often result in wasted power due to an excessive value. Sometimes it can also lead to performance problems if the operational voltage is set too low.
Current best practices cannot accurately accommodate precise individual chip requirements. He explains that design must take worst case conditions into account and finding the minimal required voltage per chip is very costly from a test-time perspective. And beyond that, the optimal Vmin over the chip’s lifetime will change due to effects such as changing workloads, aging and stress.
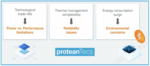
Noam then introduces proteanTecs power reduction applications. These unique technologies provide a strategy to reduce power based on personalized device assessment and real time visibility of actual voltage guard-bands. The figure below provides some of the strategies used and benefits achieved.
proteanTecs offers power reduction applications to personalize each chip’s minimum voltage requirement efficiently, including real-time visibility of the actual margins from design through production and during lifetime operation. So, over time, adjustments to the voltage supply can be done instantaneously.
A key element of the approach is embedded on-chip monitors that deliver real time information of chip operation and performance. AVS Pro provides reliability and workload-aware adaptive voltage scaling; Prediction-based VDDmin optimization per chip (during production testing) and VDDmin margin-based optimization per system are also part of the overall offering.
VDDmin is the minimum required voltage to achieve correct digital functionality. Voltage applied to a product when it runs in the field, however, needs to account for effects such as aging, temperature, workloads, and environmental conditions. Typically, these require “worst case” guard bands to be built in. But, in reality not all of these conditions take place, therefore these guard bands are wasting critical power and energy. By employing proteanTecs applications, these guardbands can be minimized and dynamically adjusted real-time. proteanTecs’ unique in-chip Agents provide high coverage and in-situ monitoring of the actual performance of limiting paths, in mission-mode. The workload aware power reduction application has a built-in safety net for dynamic adjustment should the timing margin fall critically low. Several examples of how the system works are shown, along with a live demonstration.
There is a lot of important detail shared in the webinar. I highly recommend you watch the event replay. To whet your appetite, Noam shows power savings of 8-14% for designs at advanced nodes. The live demonstration shows how the system adapts Vmin based on current conditions and how the system reacts to an under-voltage situation.
Dr. Joe McPherson, CEO, McPherson Reliability Consulting spoke next then discusses the reliability impact of power reduction. He explains the details of how chip temperature is reduced with power reduction. McPherson then explores the details of how reduced temperature impacts chip lifetime. He presents some eye-popping statics about chip lifetime increase through power induced temperature reduction. The improvement is based on the failure mechanism (e.g., hot carrier, bias temperature instability, interconnects). He explains how a 15% chip power reduction can translate to a 20 – 90 percent improvement in chip lifetime. This should get your attention.
Going beyond temperature, McPherson describes the impact of lower voltage and the associated thinner oxides. Here, the impact on device lifetime can be measured in hundreds of percent improvement. Quite impressive.
Alex Burlak, vice president of Test & Analytics at proteanTecs, concludes the webinar with details of how proteanTecs implements prediction-based VDDmin optimization for chip production and VDDmin margin-based optimization for system production. During ATE testing, typical testing requires multiple tests to identify the minimum required voltage at which the chip will still pass. In order to get the most accurate voltage, test-time becomes long and expensive. So customers must compromise to either run long tests or apply excessive VDD without ideally optimized voltage. proteanTecs offers a technique in which per-chip VDDmin application leverages an automated trained ML prediction model which eliminates the need to run a full test but will assign the correct minimum voltage to achieve the best power optimization.
Additionally, at system level testing, functional workloads or operations are often different than those made by ATE assumptions which usually rely on structural tests. Therefore, the guard bands provide a safe solution to in-field operation. Leveraging the Agents, by measuring the timing margin during functional workloads, proteanTecs can recommend a voltage optimization per chip or per system to further optimize VDDmin. Alex’s presentation is supplemented with live demonstrations of how proteanTecs delivers these capabilities.
Noam concludes the following compelling points about proteanTecs power reduction solutions:
- This approach goes beyond traditional AVS by leveraging embedded agents and real-time margin monitoring
- Optimized power and performance during production and lifetime operation
- Ensured reliability without risk
- Lifetime extension of devices – less power, less heat, longer lifespan
- Already deployed in custom systems, demonstrated up to 14% power savings
To Learn More
There is a lot of relevant and useful information presented in this webinar. If power, heat and device lifetime are important for your next design, this webinar will help provide many new strategies and approaches. You can access the webinar replay here. Or you can learn more about AVS Pro™ in this link.
Webinar Presenters
The topics covered in this webinar go deep into the testing, characterization and performance of advanced semiconductor devices. The graphic at the top of this post illustrates some of the significant challenges that are discussed. The team of presenters is highly qualified to discuss these details and did a great job explaining what is possible with the right approach.
Noam Brousard, vice president of solutions engineering at proteanTecs. With over 20 years of experience in System/Hardware/Software product development and management, consumer electronics, Telecom, mobile, IoT systems and silicon, Noam joined proteanTecs in August 2017, soon after it was founded. Before joining proteanTecs, Noam held VP R&D position at Vi, and senior technical positions at Intel Wireless Innovation Solutions, Orckit and ECI Telecom. Noam holds a M.Sc. in Electrical Engineering from Tel Aviv University and a B.Sc. in Electrical Engineering from Ben Gurion University.
Dr. Joe McPherson, CEO, McPherson Reliability Consulting. Dr. J.W. McPherson. Dr. McPherson is an international and renowned expert in the field of Reliability Physics and Engineering. He has published over 200 scientific papers, is the author of the Reliability Chapters for 4 books and has been awarded 20 patents. Dr. McPherson was formerly a Texas Instruments Senior Fellow and past General Chairman of the IEEE International Reliability Physics Symposium (IRPS) and still serves on its Board of Directors. He is an IEEE Fellow and Founder/DEO of McPherson Reliability Consulting, LLC. Dr. McPherson holds a PhD degree in Physics.
Alex Burlak, Vice President of Test & Analytics at proteanTecs. With combined expertise in Production Testing and Data Analytics of ICs and system products, Alex joined proteanTecs in October, 2018. Before joining the company, Alex held a Senior Director of Interconnect and Silicon Photonics Product Engineering positions at Mellanox. Alex holds a B.Sc. in Electrical Engineering from The Israel Institute of Technology, Technion.
Jennifer Scher, Content and Communications Manager at proteanTecs. Jennifer moderated the event, including an informative live Q&A session from the audience. Jennifer spent over 20 years in product and solution marketing at Synopsys.