
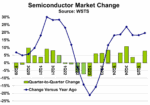
The global semiconductor market in 2Q 2025 was $180 billion, up 7.8% from 1Q 2025 and up 19.6% from 2Q 2024, according to WSTS. 2Q 2025 marked the sixth consecutive quarter with year-to-year growth of over 18%.
The table below shows the top twenty semiconductor companies by revenue. The list includes companies which sell devices on the open market. This excludes foundry companies such as TSMC and companies which only produce semiconductors for their internal use such as Apple. The revenue in most cases is for the total company, which may include some non-semiconductor revenue. In cases where revenue is broken out separately, semiconductor revenue is used.
Nvidia remains the largest semiconductor company based on its forecast of $45 billion in 2Q 2025 revenue. Memory companies Samsung and SK Hynix are second and third. Broadcom is fourth and long-time number one Intel has dropped to fifth.
Most companies reported solid growth in 2Q 2025 revenues versus 1Q 2025, with a weighted average increase of 7%. Memory companies showed the largest increases, with SK Hynix up 26%, Micron Technology up 16%, and Samsung up 11%. The healthiest revenue gains among the non-memory companies were Microchip Technologies at 11%, STMicroelectronics at 10%, and Texas Instruments at 9.3%. Five companies saw revenue decline from 1Q 2025.
Almost all the companies providing guidance expect healthy growth in 3Q 2025 revenues versus 2Q 2025. Again, the biggest gains are from memory companies, with Micron projecting 20% and Kioxia projecting 30%. Both companies cited demand form AI applications as the key driver.
STMicroelectronics guided 15% revenue growth with all its end markets up except auto. AMD projects a 13% increase driven by AI. The other six companies providing revenue growth guidance range from 1.7% to 7.7%. The only company expecting a revenue decline is MediaTek, with a drop of 10% in 3Q 2025 due to a weak mobile market.
AI remains the highest grow driver. Many companies are seeing upticks in their traditional markets. Some companies are experiencing growth in automotive revenues while other companies see automotive continuing to be weak. In their conference calls with financial analysts, most companies cited the uncertainties around tariffs and global trade as areas of concern.
The strong semiconductor market growth in the first half of 2025 practically guarantees double-digit full year growth. Recent forecasts are generally in a narrow range of 14% to 16%. WSTS revised its June forecast from 11.2% to 15.4% based on the 2Q 2025 data. We at Semiconductor Intelligence (SC IQ) remain cautious due to the uncertainty about global trade. But based on the strong first half of 2025, we are raising our 2025 forecast to 13% from the May forecast of 7%.
Projecting the impact of U.S. tariffs on global trade is difficult due to the frequent changes in threatened tariffs and implemented tariffs. In the case of China, the Trump administration in April threatened tariffs as high a 145%. In May, the administration put a 90-day pause on the higher tariffs and set tariffs on China at 30%. This week, the pause was extended until November.
Direct tariffs on semiconductors are very uncertain. Earlier this month, President Trump announced the U.S. will impose a 100% tariff on imports of semiconductors. He said companies that commit to building semiconductors in the U.S. will not face tariffs. Details of the plan have yet to be announced.
This month the Trump administration reached an agreement to provide export licenses for Nvidia and AMD to ship certain AI chips to China. The companies will be required to pay 15% of the revenue from these sales to the U.S. government. The legality of this agreement is questionable. The U.S. Constitution prohibits Congress from putting taxes or duties on exports. EE Times describes the deal as “unique”.
One area which has already seen an impact from tariffs is smartphones. As we have noted in previous newsletters, U.S. imports of smartphones have been dropping dramatically in recent months. 2Q 2025 U.S. smartphone imports dropped 58% in dollars and 47% in units from 1Q 2025. Smartphone unit imports from China declined 85%. Although there are currently no tariffs on smartphone imports, the threat of tariffs has had a significant impact. Canalys estimated 2Q 2025 U.S. smartphone sales were down about 20% from 1Q 2025. Many of the 2Q 2025 sales came from existing inventory. However, U.S. smartphone sales should drop significantly in the second half of 2025. Despite the drop in exports to the U.S., China smartphone manufacturing has remained strong, with unit production in 2Q 2025 up 5% from 1Q 2025.
The current semiconductor market is strong. Ongoing global trade disputes are a significant concern, but so far have not had a meaningful impact. The Trump administration tariff threats may become, to quote Shakespeare’s MacBeth, “sound and fury, signifying nothing.”
Bill Jewell
Semiconductor Intelligence, LLC
billjewell@sc-iq.com






{kind=link}
{kind=link}