
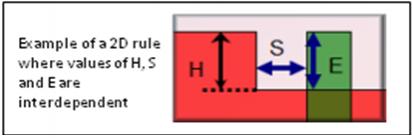
In the world of sub-40nm IC design, as feature size decreases with each new process node, it becomes increasingly difficult to migrate a layout to a new process technology. Too many factors impact manufacturability and yield. At each new process node, to make sure that a given layout is manufacturable and yields well, it is subject to rules that grow in number, type and complexity. Manual migration of a layout from one process technology to another is extremely complex and time-consuming. When an entire library must be migrated, automation is the only practical choice.
“Today’s 28nm and 20nm technologies present many new and tougher challenges for physical implementation. A library that is competitive from density, routability, reliability and variability perspectives and at the same time respects all new technology design rules is very hard to design manually in a timely manner. Furthermore, frequent changes and updates to new technology design rules make it even more challenging to keep up with manually” explained Coby Zelnik, Sagantec‘s president and CEO. “nmigrate is an automatic layout migration, compaction and optimization solution that is proven to successfully handle all these requirements and updates, delivering optimal results that are design rule clean” Zelnik concluded.
nmigrate is based on innovative 2-D layout optimization technology using dynamic compaction that generates an accurate layout solution optimally satisfying all design rules and constraints. The ability to optimize a layout considering all 2D rules, constraints and cost functions, make it versatile, and suitable for different applications including migration, DRC correction and DFM.
2-D Optimization:The compaction technology allows all 2D rules and effects to be processed in one run, making optimal tradeoffs between constraints and cost in all directions. Including design rules involving multiple shapes where measurement in one dimension influences multiple rule values in the other dimension. Such 2D optimization engine is essential to effectively handle mandatory and DFM rules
Cell optimized for preferred rules: M1 before/after
Self Steering Dynamic Optimization:Advanced technology design rules may have multiple different and discontinuous correct solutions. When polygons and edges start changing position as part of process migration or DRC correction, finding the optimal solution considering all possible discontinuous position configurations is very difficult and requires an engine that can make the right choices and decisions in a multi-dimensional dynamic environment. nmigrate is designed to dynamically evaluate rules and self-steer the engine to achieve the best optimization.
Illustrated are few examples for rules that require dynamic choices and self- steering optimization:
- Width and common run length dependent spacing rule
- Contact groups and via array rules where each spacing value depends on the number and spacing of other shapes.
- Coloring: Due to the printability challenges in 20nm technology new types of rules have been introduced, including DP coloring, A-B spacing rules and auto breaking of odd cycle color conflicts.
Design Rule Changes: New process technology rules change often as the process matures. Implementing each such change manually is time-consuming and error-prone. nmigrate automates the process and enables quick updates with no time penalty. See below example of a pitch change from 130 to 135nm
Creating Derivative Libraries:With nmigrate, creation of derivative libraries is quick and automated (for example creation of 8-track library from an existing 9-track library).
Full Chip DRC Correction
Often a complete design needs to undergo updates of a few design rules close to tape-out, or even after tape-out for yield enhancement. Similarly, often migrating to a different foundry requires only changing a few design rules. nmigrate uses a fast clip-and-fix flow that is completely scalable by using multiple CPUs.
Applications
- Process migration
- Foundry re-targeting
- Handling design rule changes
- Creating derivative libraries
- DFM optimization
Key Features & Benefits
- Automatically delivers 28nm and 20nm DRC-clean layout using 2D optimization
- Most optimal results guaranteed by self- steering and dynamic evaluation engine
- Sophisticated cost function system optimizes layout for yield, variability, reliability and other design metrics
- Supports user-defined constraints and layout templates
Sagantec is the leading EDA provider of process migration solutions for custom IC design. Sagantec’s EDA solutions enable IC designers to leverage their investment in existing physical design IP and accomplish dramatic time and effort savings in the implementation of custom, analog, mixed-signal and memory circuits in advanced process technologies.
These solutions have been used commercially by tier-1 semiconductor companies, and have been proven to reduce layout time and effort by factors of 3x to 20x and enable dramatically faster introduction of IC products in new technology nodes.
Sagantec has booth #1402at the 2012 Design Automation Conference. See you there!







{kind=link}