


 With an estimated 7 billion connected devices, the demand for rich content, including video, games, and mobile apps is skyrocketing. Service providers around the globe are scrambling to transform their networks to satisfy the overwhelming demand for content bandwidth. Over the next few years, they will be looking to network equipment manufacturers to provide high performance and cost effective products that will ultimately fulfill the promise of 100G Ethernet. However, network equipment manufacturers must grapple with the stark reality that aggregated line speeds (and as a result the requirements on aggregate networking processing speeds) have grown at over 25% CAGR in the past decade. This has dwarfed the growth rate of SoC memory clock speeds.
With an estimated 7 billion connected devices, the demand for rich content, including video, games, and mobile apps is skyrocketing. Service providers around the globe are scrambling to transform their networks to satisfy the overwhelming demand for content bandwidth. Over the next few years, they will be looking to network equipment manufacturers to provide high performance and cost effective products that will ultimately fulfill the promise of 100G Ethernet. However, network equipment manufacturers must grapple with the stark reality that aggregated line speeds (and as a result the requirements on aggregate networking processing speeds) have grown at over 25% CAGR in the past decade. This has dwarfed the growth rate of SoC memory clock speeds.
System designers can crank up processing performance with faster processer speeds, parallel architectures, and multicore processors. However, if memory performance cannot keep up, processors will have to wait for memory requests to execute, which will cause the system to stall. Memory performance must be increased. Since memory clock speeds are limited, the next logical step to boost performance is to use multiport memories, which allow multiple memory access requests to be processed in parallel within a single clock cycle.
For example, with the recent launch of 100G Ethernet, there is a need for line cards supporting two or four 100G links per card. As aggregated line rates approach 400 Gb/s (via the more traditional aggregation of 40 10Gb/s ports, or 4 100 Gb/s ports in future), the networking datapath needs to support 600 million packets per second i.e., 1200 million 64-byte cells per second in the worst case. This requires 1.2 GHz clock frequency or more, depending on the design, which is not possible with any single-port memory available today.
While multiport memories have traditionally had a reputation for being difficult to implement, new technology now makes multiport memories an attractive choice for high performance networking applications. At Memoir we have developed Algorithmic Memory™, essentially a configurable multiport memory that can be synthesized by combining commercially available single-port memory IP with specialized memory algorithms. These algorithms employ a variety of techniques within the memory to increase performance such as caching, address-translation, pipelining, encoding, etc. which are all transparent to the end user. The resulting memories appear as standard multiport embedded memories (typically with no added clock cycle latency), that can be easily integrated on chip within existing SoC design flows.
Algorithmic Memory addresses the challenges of memory performance at a higher level. It allows system architects to treat memory performance as a configurable characteristic with its own set of trade-offs with respect to speed, area and power. For example, it is possible to increase the performance of single-port memory by 4X, as measured in memory operations per second (MOPS), by using the single-port memory to generate a four-port Algorithmic Memory.
In addition, the read and write ports of these multiport memories can be configured based on the application requirement. For example, as shown in Figure 1, multiport memories with four read ports (e.g.: 4Ror1W per cycle multiport memory) can be used for applications such as lookups which primarily need read performance, and perform occasional writes. Similarly, other applications such as Netflow, Statistics Counters, etc. (which need equal read and write performance) can use 2R2W multiport memories.
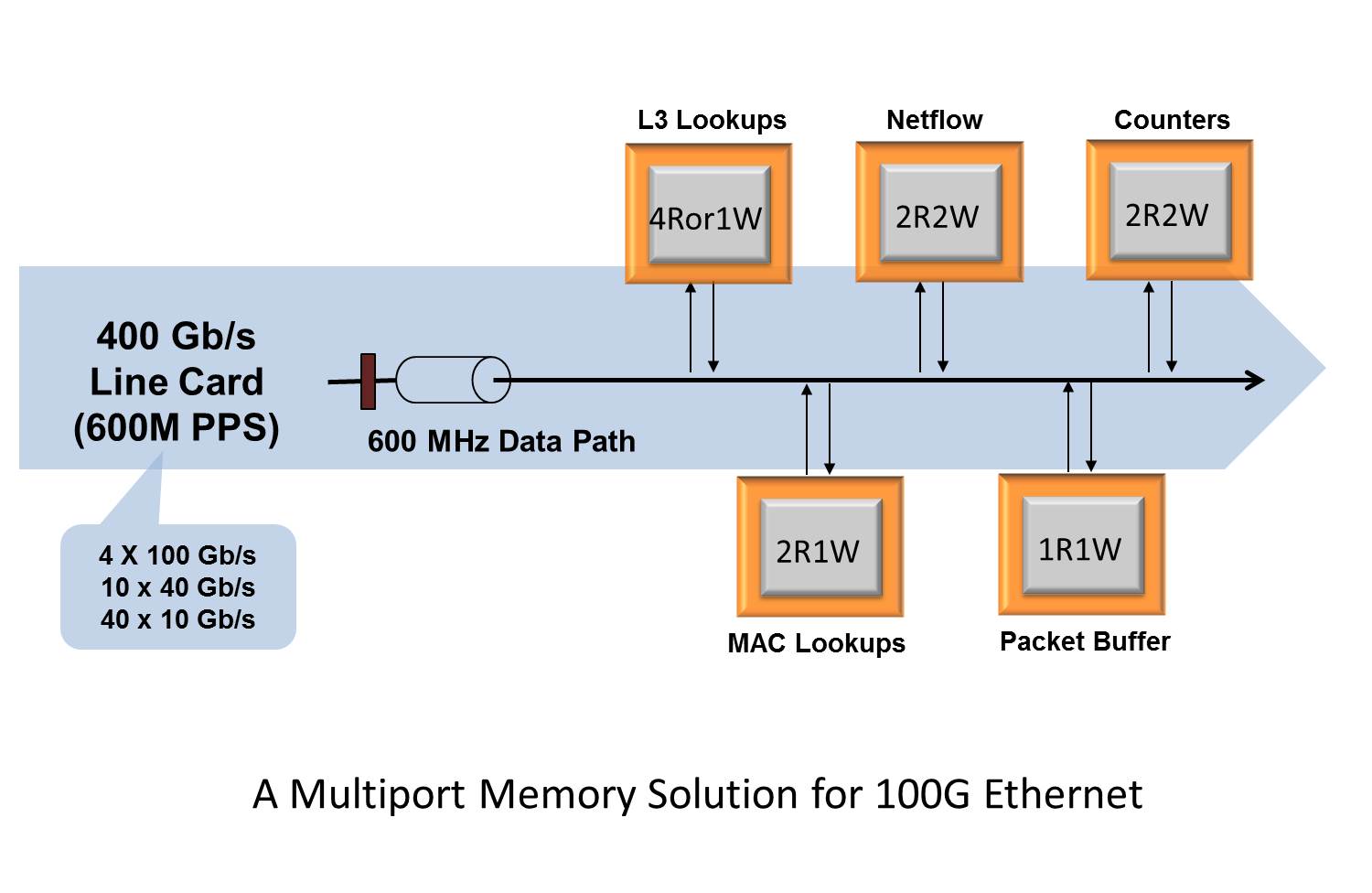
Figure 1. There are no single-port memories that can support networking data-paths with 600M packets (or 1200M 64-byte cells/sec) per second. Four-port Algorithmic Memory can deliver up to 2400 million MOPS at 600 MHz as required for next generation 10G/100G Ethernet systems. Memory read/write ports can also be configured for application specific requirements, including asymmetrical reads and writes.
Depending on the memory IP core that is selected, it is possible to create memories with performance increases of up to 10X more MOPS. In some cases, Algorithmic Memory technology can also be used to lower memory area and power consumption without sacrificing performance. This is because there is a significant area and power penalty when a higher performance memory is built using circuits alone. With Algorithmic Memory technology, it is possible to take a lower performance memory (which typically has lower area and power), incorporate memory algorithms, and synthesize a new memory. The new Algorithmic Memory achieves the same MOPS as a high performance memory built using circuits alone, but can have lower area and power. The area and power savings are even more beneficial for high performance networking ASICs (typically over ~400mm[SUP]2[/SUP] and over 80W in power) that are architected at the inflection point of cost, power, yield and buildability.
Since they are implemented as a soft RTL, Algorithmic Memories are compatible with any process, node, or foundry. The memories use a standard SRAM interface with identical pinouts, and integrate into a normal SoC design flow, including ASIC, ASSP, GPP and FPGA implementations.
In summary, memory processing tends to be the weak link in increasing network performance. Networking wire speeds are increasing faster than the increase in memory clock speeds. Networking gear is very memory intensive and often requires several memory operations per packet. The bottom line is that faster processors alone cannot improve network performance unless we are able to increase the total MOPS. As rates approach 400 Gb/s, there are no practical viable memory solutions, other than to use multiport memories. As rates approach 400 Gb/s, there are no practical viable physical memory solutions. Algorithmic memories (which build on physical memories), offer a scalable and versatile alternative, that can help alleviate the performance challenges of aggregated 100G Ethernet and beyond.





TSMC CoWoS versus Intel EMIB Semiconductor Packaging