

The cell phone phenomena has catalyzed the technology growth and coaxed the hardware and software to work more closely. The Apple effect further directed this technology growth to focus on enhanced user experience. The emphasis has been primarily on the display and touch aspects of the designs with limited adoption on other areas. The handsets have moved from buttons to touch display and the next wave under discussion is gesture recognition. Interestingly, direct human to human interaction is mainly through speech while human to machine interface still relies more on passive modes. As a first step to enable this, there is a need for the hardware to respond to the voice commands (pre-defined to start with). A ‘Speech Recognition’ hardware unit is required to interpret the human speech and translate it into text or commands. The applications include call routing for customer service calls, controlling consumer appliances or in-car systems, preparing transcripts and content navigation on cell phone.
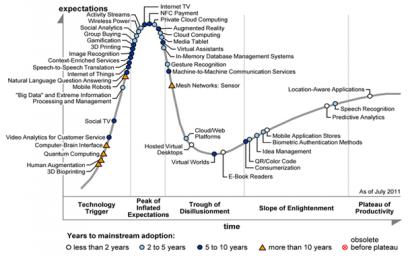
Gartner’s annual Hype Cycle Special Report on technologies and trends from cross industry perspective in 2011 revealed that it will take 2 to 5 years for mainstream adoption on this technology.

The main challenges preventing it from moving ahead include –
Developing a programmable user interface – There are a variety of languages across the globe and even for a single language the pronunciation varies widely. The solution should be able to overcome this hurdle with an easy to use interface.
Power – Speech Recognition is a computationally intensive technology requiring several million operations per second. Power dissipation is the key and limits the usage of SW based solutions especially in battery powered devices where continuous use of speech recognition or “Always Listening” as it is popularly known can drain the battery in no time.
While multiple groups might be working towards a solution, one from India claims to have a sophisticated solution available with them. 3iLogic-Designs, founded by seasoned professionals in 2011 recently uploaded multiple videos of their prototype solution. The product name is SimSim and is supposed to be the world’s first ultra compact language & speaker independent, zero connectivity, synthesizable speech recognition core with configurable vocabulary and grammar support. A high level block diagram of the SimSim architecture is given below –
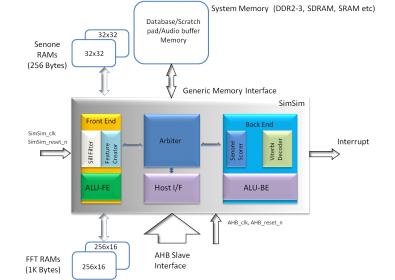
The salient features include –
- Highly accurate speaker independent Speech Recognition
- Scalable vocabulary
- Java Speech Grammar (JSGF) support
- Based on proven HMM technology
- Language independent architecture
- 16Khz/8Khz audio support
- VAD (Voice activity detection) support with auto calibration for ambient noise
- Processor-independent, stand-alone operation
- Independent of external memory type (DDR2/3, SDRAM, SRAM etc.)
- Very compact solution in terms of memory requirements
- Implemented with 135K Gates
The list above makes SimSim an ideal solution for localized Vocal-UI solutions for Cell Phones, Digital Cameras, PNDs, MFPs, Watches, Remote Controls, Microwaves, Washing machines etc.
Such a technology enhances user experience for regions with tech savvy population and becomes a prime selling point for the next generation of devices. Along with that it can also drive technology adoption in developing geographies. Countries like India where a majority of consumer market is still untapped primarily because of diversity in the languages spoken and high ramp up learning time on technology, this solution can be a game changer!
The magic of “SimSim” from Arabian Nights is awaiting to open the doors of fortunes once again 🙂





TSMC CoWoS versus Intel EMIB Semiconductor Packaging