
I have been at SNUG for the last couple of days. The big announcement is IC Compiler II. It was a big part of Aart’s keynote and Monday lunch featured all the lead customers talking about their experience with the tool.
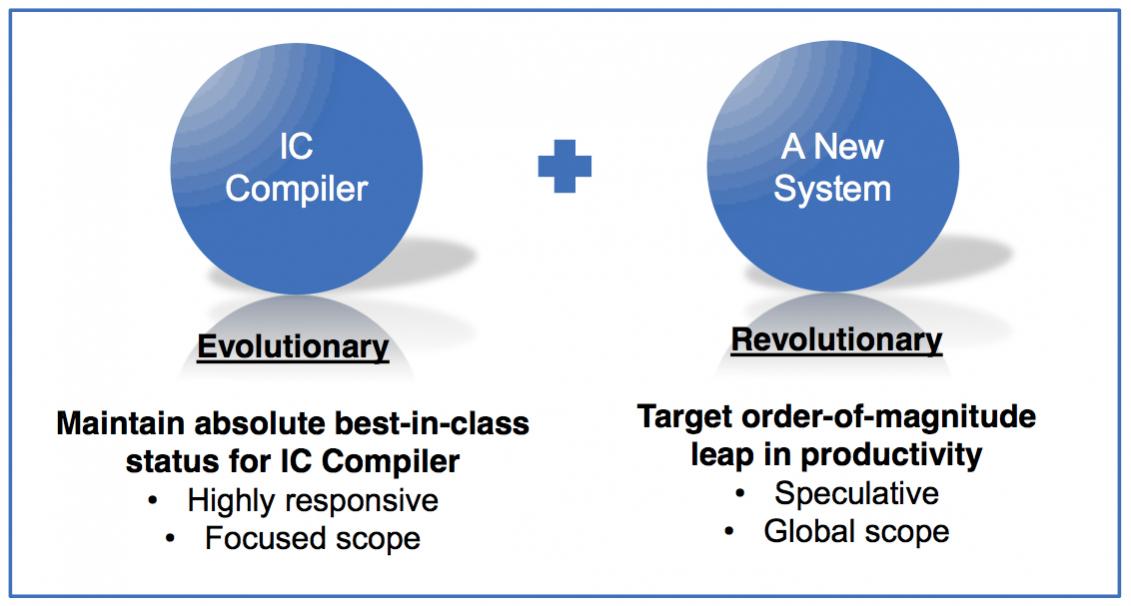
 The big motivation for IC Compiler II was to create a fully multi-threaded physical design tool that will scale well on multi-core processors and large server farms. The original IC Compiler, what is now called IC Compiler I, was written in the era when Intel would produce a faster microprocessor each year and so the tool pretty much scaled automatically just by waiting.
The big motivation for IC Compiler II was to create a fully multi-threaded physical design tool that will scale well on multi-core processors and large server farms. The original IC Compiler, what is now called IC Compiler I, was written in the era when Intel would produce a faster microprocessor each year and so the tool pretty much scaled automatically just by waiting.
Synopsys actually did something pretty difficult to achieve. They took several years to create a new version of IC Compiler but at the same time they had to aggressively continue development of IC Compiler I, in particular adding support for double patterning needed for 20nm designs. That required two separate teams of developers. The goal with IC Compiler II is to increase productivity 10X by creating a tool that runs 5X as fast and that requires half the number of iterations to reach closure.
 Several of the lead customers talked about their experiences using the new tool. LSI used their network processor Axxia as a test vehicle. Panasonic used a large TV bridge SoC. ST used a 6M instance FD-SOI consumer device. Imagination used sub blocks of their Power VR ray-tracing Wizard chip.
Several of the lead customers talked about their experiences using the new tool. LSI used their network processor Axxia as a test vehicle. Panasonic used a large TV bridge SoC. ST used a 6M instance FD-SOI consumer device. Imagination used sub blocks of their Power VR ray-tracing Wizard chip.
All of these customers had similar experiences. They used an existing design to try out the tool and gain confidence, but the results were spectacularly better that they immediately started to use IC Compiler II for production designs. It still requires a hybrid flow since not all the routing capability is yet in IC Complier II. However, the floorplanning, time-budgeting and so on is all working.
The results are impressive. LSI, for example, went from iterating daily versus weekly, with floorplanning run-times of 17 hours compared to 5 days with IC Compiler I, clock tree optimization in 29 hours versus 6 days and with 40% fewer driver cells.
As Mark Dunn of Imagination put it, this is “disruptive technology.” His design is 20M instances with 1600 macros. Floorplanning is 10X faster and requires just half the memory. IC Compiler II is the standard for hard designs.
Pascal Teissier of ST uses it almost completely automatically for floorplanning, 90% in his estimation, with just a small amount of guidance for some datapath. His design has 4.6M instances. Block shaping takes 5 minutes, macro planning 75 minutes and analysis and validation 8 hours. On another design they do placement and clocking for a 2.3M instance design in 7 hours.
IC Compiler I will continue to be supported and continues to be the tool of choice for older process nodes. IC Compiler II will be the tool of choice for 28nm and below, especially for FinFET designs that are both large and have some additional complexity associated with extraction.
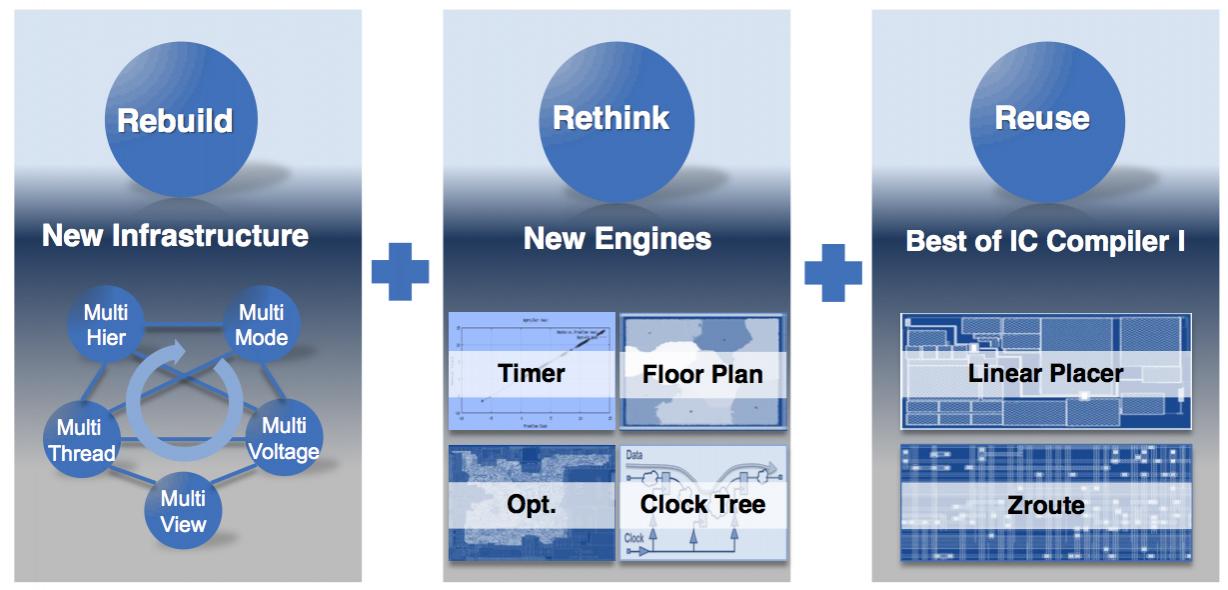 As Antun Domic pointed out, it is not really correct to call it “place & route” any more, that is just one small part of the physical design process. The tool has a completely new “database” infrastructure, new engines for floorplanning, and clock tree, keeps the existing Zroute and linear placer. So, in fact, it is everything except place and route that is new!
As Antun Domic pointed out, it is not really correct to call it “place & route” any more, that is just one small part of the physical design process. The tool has a completely new “database” infrastructure, new engines for floorplanning, and clock tree, keeps the existing Zroute and linear placer. So, in fact, it is everything except place and route that is new!
More articles by Paul McLellan…




Comments
There are no comments yet.
You must register or log in to view/post comments.