
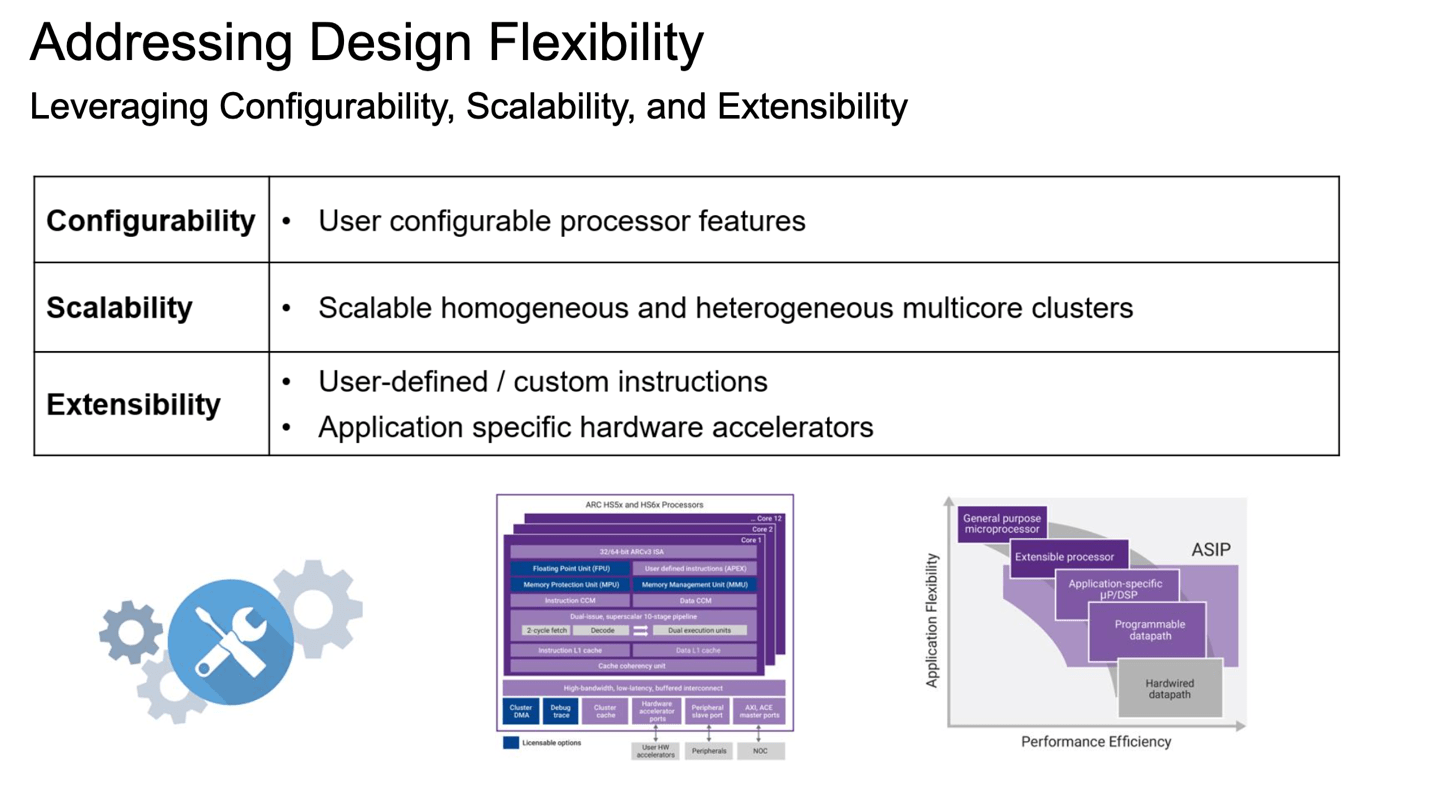
Configurable processors are hot now, in no small part thanks to RISC-V. Which is an ISA rather than a processor, but let’s not quibble. Arm followed with configurability in Cortex-X. Both were considerably preceded (a couple of decades) by Synopsys ARC® RISC CPUs and CEVA DSPs. Each stressed configurability as a differentiator over other embedded processors and have enjoyed continued success in leading with that capability. A few months ago, Synopsys hosted a useful backgrounder on the Why and How of configurability, centered naturally around ARC processors.
Why Configure?
There are multiple drivers. Earbuds and more generally wearables need to be ultra-low power with processing maximally optimized down to or below the instruction level. In the cloud and network infrastructure, compute is becoming disaggregated to reduce latencies and power. Also demanding optimization to deliver to those goals. In datacenters, servers now offload initial database searches to smart SSDs, for search and wear prediction. Open RAN networks distribute intelligence and storage across the network to be fast and responsive yet must be super cost effective.
Support for car to infrastructure (V2X) communication is a fascinating example worth a little more backstory. The US Secure Credential Management System (SCMS) is a leading candidate for V2X certification and builds on a public/private key technique called unified butterfly keys. This allows a second party to generate a sequence of public keys for which only the originator knows the private keys. Unsurprisingly, this system heavily stresses performance. There are loop operations in the process which would prevent meeting those goals using conventional software algorithms running on a processor. These performance-critical sections must be accelerated in some manner.
Extending the Processor ISA
Part of the reason these loops are slow is the overhead in the CPU pipeline for each instruction. Fetch, decode, dispatch, speculation, execute, write-back. If an instruction sequence is compressible into one or a few instructions, that can save significant time by minimizing this overhead. There can also be other advantages such as special processing for very long word arithmetic.
The Synopsys ARC APEX technology enables adding custom instructions to meet this need. A developer builds (through APEX) Verilog for those instructions. This can connect to standard processor resources like condition codes, registers, and signals. APEX will insert the Verilog in the ARC core, essentially parallel to the ALU. When an instruction decodes to this special operation, it will be directed to the custom logic rather than the ALU. Otherwise, the rest of the CPU and compiler flows work the same. An easy way to fold custom instructions natively into the core.
I should add that Synopsys provides other options for optimization: configurability in the core processor and parallelism through muti-core implementations. Also support for closely coupled customer accelerators which can connect directly to shared cache and share memory.
Is it Worth the Effort?
Rich Collins (Director of Product Marketing) highlighted one example in the talk: an optimization for a red-black tree algorithm (balancing trees) for a storage application. Here, designers were able to reduce execution time (and correspondingly power) by 50% with little added area. I don’t have numbers for the SCMS design (referenced earlier in this article); these are too difficult to disentangle from their algorithm improvements. Clearly, they depended heavily on ARC and APEX to make their design feasible.
Interesting stuff. You can watch the webinar HERE.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.