

 It is important when talking about a market to first establish the need and potential growth, then determine how the market is being served. This requires examining product features and services offered.
It is important when talking about a market to first establish the need and potential growth, then determine how the market is being served. This requires examining product features and services offered.
Part one of my design integrity investment thesis looked at the emergence of Verification 3.0 and the pivotal role that the Portable Stimulus Standard (PSS) plays.
In part two, we explore the identification of value propositions for a PSS offering. In the broad sense there are always three: Is it faster? Is it more cost effective? Is it better?
As a reminder, this thesis series is not about the introduction of a new language or tool. It is about reimagining functional verification, rearchitecting notions about verification from the ground up into something that is suitable for today’s much more complex systems with the necessary extensibility for the future.
Most of the tools and methodologies being used today were designed more than 20 years ago. Chips were a tiny fraction of the size and complexity compared to the verification task being tackled today. Existing languages and methodologies have scaling problems and do not address many of the requirements being placed on them.
An investment in Verification 3.0 is about how tools and methodologies will grow over time and how they will change both design and verification flows. This investment thesis has multiple angles.
For me as an investor, it is looking at startup companies trying to understand if the market they are looking to serve has significant opportunity for a new and disruptive technology.
For the market, it is a way to competitively enhance their development flows so that they can produce higher-quality products in a fraction of the time with greater confidence. The only companies that have anything to lose are legacy tool providers if they are unable to adapt to the long-term business implications.
In any case, the consumer benefits, either through enhancements to existing solutions or new and disruptive approaches. Competition always improves the breed.
It all starts with the design integrity model. A design integrity model captures the primitive capabilities of a design. The Accellera Portable Stimulus Standard provides a language to define this model.
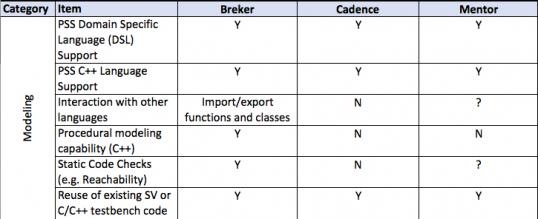
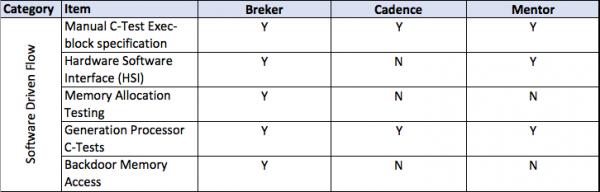
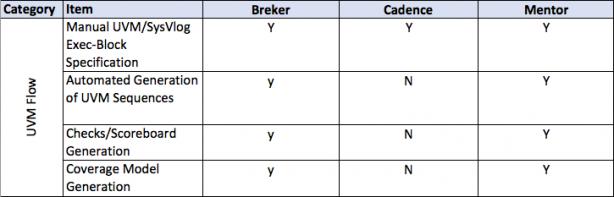
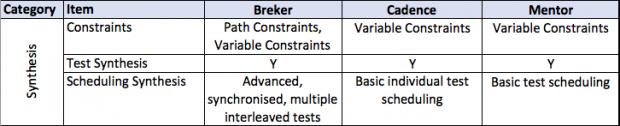
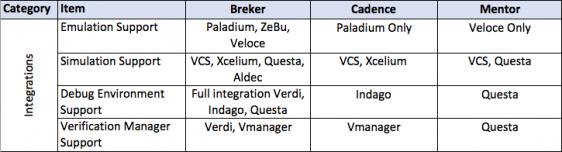
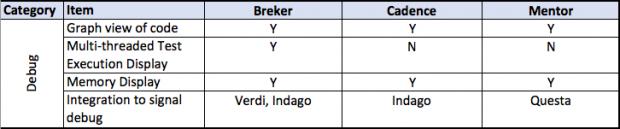
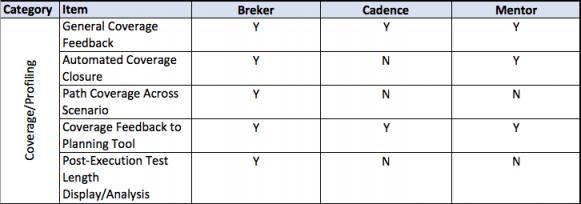
This thesis talks about facets of a verification flow driven by a design integrity model, in general terms and then more detailed. It provides a matrix of some central attributes associated with that. The matrix uses the publicly stated capabilities of the three major tools in the market today. I am sure it is incomplete and invite others to help fill in this table and to extend it where they see other significant aspects.
A full discussion of each of the comparative lines is beyond the scope of this document.

Why a Standard?
The industry usually waits until a de facto winner has emerged to drive the creation of a standard. Since that did not happen with Portable Stimulus, it is perhaps a fair question to ask why? What did the industry have to gain by doing this during the formative stages of graph-based verification? What is the downside?
Some have suggested that the creation of a standard makes user adoption easier. It takes away their fear of getting locked into a proprietary language and provides vendor portability. Needs and features get vetted in public for the good of all. This is most certainly a consideration for a user. Basically, if the return on investment is there, they will adopt it even without a standard. Companies that have run headlong into a brick wall will do whatever it takes to hurdle that barrier and portability is not on the top of their priority list. This is how de facto standards come into existence.
Several advantages are associated with having a standard. For Portable Stimulus, the biggest change, by far, is that this standard will affect everything in the design and verification flow, bigger than any one company can handle, even the large established players.
My concentration is on the verification flow, and even this can only be accomplished with several companies. As I talked about in part one, the design flow will change as well when verification becomes the leading flow rather than the lagging flow. Without a common anchor point between the tools, it will be impossible for Verification 3.0 to be achieved and even more difficult for companies to start work on the reimagined design tools that will go along with it.
Tapping the Hive Mind
Let’s start by discussing the Innovator’s Dilemma.
Breker has invested in graph-based verification technologies for more than a decade. During that time, it developed several generations of tools, each based on collaborations with early adopters of the technology. Over time, requirements fed into the development team until a better model, or a more generalized model emerges. Then the technology takes a leap forward.

A potential problem with this isolated development is that tools become more focused and specific over time as they address the user base and potentially become less attractive to users with a different set of requirements. Startups often get trapped in producing a tool that works well for a specific user, but can become too focused for general utility. This is a classic part of the Innovators Dilemma. By bringing the technology to a standards body, a much wider audience participates in the development of the standard. The experiences, from companies such as Breker, demonstrate what has been proven to work and acts as foundational technology. The technology is then viewed by a much wider audience than may have been interested in the current tools and the breadth of the solution can be widened.
As an example, none of the EDA vendors are security experts and no established tool chains deal with security issues. However, there is a large group of academics and industry experts working on solving this problem. Sooner or later, verification will play a role in ensuring that security issues are addressed. Formal verification has started making inroads here and it is valuable that this knowledge is incorporated into the developing Portable Stimulus Standard.
For something as important as future EDA flows, it was essential to get the hive mind working on the problem as quickly as possible. This stops a single EDA vendor from forcing the technology down a path that would restrict its ultimate capabilities and role in the flows that will be required. This is exactly the battle that has been going on within the Accellera committee.
In addition, the initial focus was on dynamic execution engines. Little thought was given to formal verification, one of the fastest growth areas of verification. It is critical that this is brought in early and if there are problems, they need to be solved now rather than waiting until the standard is more fully developed.
Amortized Education
One of the big advantages of a standard is that education is not taken on by a single company. Instead, the costs can be amortized across the industry, making the cost of developing tools cheaper, speeds up the adoption process and enables users to become productive with the technology faster.
There is a slight downside to this. In the early days of a new standard, companies may be struggling to implement the entirety of the standard or may not fully understand the implications of pieces of the standard. This has happened several times within the industry, such as with VHDL and more recently with SystemVerilog. Each vendor attempts to stress the importance of the elements that they have working in their tools and creates misinformation about the pieces they are struggling with. We see elements of that going on today.

Current status
Version 1.0 of PSS was released in June 2018. Standards are always a herculean achievement for the committee, Accellera and the industry. It provided the framework on top of which additional capabilities can be layered. It gives us something to build on.
The first release of the standard, however, is incomplete. It is not capable of meeting all the requirements of the existing user base and forced vendors with established users to go beyond the standard.
While both inevitable and unfortunate, it does not negate the advantages of a first release of the standard. It will accelerate the rate at which other vendors are able to ascertain the suitability of the standard for their pieces of the flow. Additionally, it will make it possible for them to bring their requirements to the committee faster than possible if the standard had first been perfected for its initial application.
It is crucial that the industry keeps moving forward rather than accepting that PSS will only address the current use cases. It is clear that PSS has the ability to unify large amounts of the incumbent verification methodology and provide additional value to parts of the design and implementation flow that have not participated in functional verification.
In the formative days of the PSS committee, committee members defined two axes of reuse: horizontal and vertical. Filling out both of axes will take time and each vendor is currently focusing on a few points in that solution space. Implications of those axes are discussed in the next section. Slide courtesy of Breker.
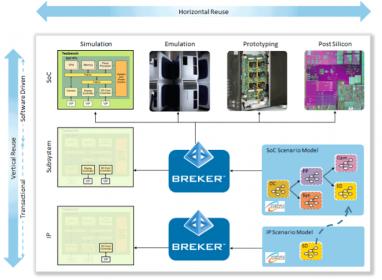
Vertical Reuse
Vertical reuse is something of a luxury in terms of functional verification. Existing verification methodologies looked at the design as being essentially flat. However, within the 20 years since these methodologies were created, design has changed. The IP industry is also 20-years old and the majority of a chip’s surface area today is made up from reused blocks from internal reuse or third-party IP.
Little to no progress has been made in the verification flow from block to sub-system, from sub-system to full chip or from standalone hardware to hardware/software integration. Teams have to essentially replicate large amounts of work at each stage, a huge waste of time and effort.
Pieces of the development flow, refined over time without a unified verification perspective, have become highly fragmented. Verification performed at the concept stage has no bearing on implementation. The needs of users looking at system-level performance cannot be met by existing verification tools. Thus, they created their own methods and techniques. Hardware verification has given scant consideration to the integration of various layers of software, simply because existing verification methodologies almost deny the existence of processors.
Bringing about all aspects of a unified verification flow will take time. This is part of why the design flow will be affected as well. Once a full design integrity model is defined and available to all phases of the development team, benefits will build.
For example, when a scenario is defined that stresses a particular part of a design, it may have been verified on an architectural model during concept development. As the design proceeds, that same scenario can be rerun at various stages to ensure that the necessary performance is still inherent in the design and implementation. That scenario becomes a major requirement taken through the entire development flow and validated on actual silicon. If a mismatch is found, the higher-level models can be refined or improved to reflect this reality and the next generation will start from having a more precise expectation. This is reuse both within a flow and across generations of flow. Information captured during device deployment can also be fed back into the flow.
Software and hardware
When sub-systems are being verified, it is likely that they will contain a processor of some sort. Few systems, save for a few special cases, are designed today that do not contain multiple heterogeneous processors. Each may have an influential role to play in the dataflow or they could just be simple controllers. Some will only ever run bare-metal software while others may run small operating systems. Others will have full-fledged software stacks.
When it comes to verification, the hardware verification team often has to write its own software to run on these processors. This software is targeted at testing the hardware implementation, rather than providing final functionality. While complex arguments about how much production software should be used, I will not get into the intricacies here. However, most teams require that the hardware is capable of booting production code before tape-out. If that is left until the last moment, they often find time-consuming problems or incompatibilities that can result in extensive rewrites usually of the software because it is deemed easier to change.
One of the fundamental usage modes for PSS is to run tests from the inside out rather than the outside in. What I mean by this is that the processors, by their very design, have access to almost all aspects of the hardware and are perfectly placed to do most of the verification. This is different than existing methodologies where processors are removed, and transactions fed onto their busses.
The question still remains: How much production software to use? An aspect of vertical reuse is a layer called the hardware/software interface (HSI). This makes it possible to easily swap in pieces of production code or to use bare metal code developed for the purpose of hardware verification. As an example, users may want to use a production driver for a block after it has been fully verified standalone. They do not want to have to rewrite the verification model to make this change.
Top Down and Bottom Up
Around the same time that the IP industry was coming into existence, another group thought that it could create a perfect top-down flow where users started from a specification and would be able to get all the way to implementation using successive refinement steps. While that is possible for small pieces of the design, the bottom-up reuse model has become the predominant design methodology.
Aspects of a system utilize abstract models for concept verification, architectural and performance verification. Most of this work is disconnected from the rest of the functional verification flow today.
The bottom-up flow is disconnected from top-down analysis. I discussed previously the difficulty taking the verification environment for a block and reusing that for sub-system verification because SystemVerilog and UVM do not provide good forms of abstraction and encapsulation. These problems are resolved by PSS, making it possible to construct flows that bridge abstractions. It is likely that those flows will be bottom-up flows even though the initial user base for PSS is focused on system-level verification. However, once models have been created for one project, they will become useful for block-level verification in the next iteration of the flow. While this may seem to be a top-down flow, it is bottom up with reuse across projects.
IP Documentation
A side effect of a bottom-up flow is an improved methodology associated with IP. If an IP block is delivered along with a design integrity model, that verification environment can be fully integrated into higher-level verification and aspects of the model, such as coverage, span the boundary. Consider one aspect of how this could be used. If a higher-level scenario were to trigger functionality in an IP block that had not been previously verified, the user and developer of the IP could automatically be warned of the situation.
The design integrity model thus becomes a prominent piece of IP documentation used in its executable form during the remainder of the verification steps. It can also be examined when assessing which IP to purchase, where preference may be made to those that have been verified for their intended usage scenarios. This can be ascertained before delivery of the IP block.
Incremental Refinement
An elemental aspect comes from top-down development, especially its implications on the verification environment. Earlier, I discussed the need to have the design integrity model exist, at least partially, before design started, not possible currently because UVM models do not support notions of partial models.
PSS models do. Consider the early stages of a design where it may not have been decided exactly what interfaces, or versions of each interface will be supported. Initial development may assume a single interface, and this would be built into the design integrity model. All verification at that stage would utilize that interface. If a second interface was added, it would not invalidate any of the test already created, only add additional paths that may exist through the graph. While the initial tests may have to be rerun to ensure that the addition of the second interface did not break the initial set of tests, no changes have to be made to the tests themselves.
It is also possible that additional capabilities may be defined within a model over time. Again, this adds to the paths that could be chosen by a PSS solver, but does not invalidate any previously generated tests. Thus, verification can start as soon as a single valid path exists through the model, a pivotal feature of the model that will enable it to be at the forefront of the development process.
Although a top-down approach is ideal, defining a complete intent specification up front can be overwhelming. As such, PSS users today tend toward building individual scenarios as graphs and combining them into the overall specification. One advantage of PSS is flexibility –– smaller graphs can be easily combined to build larger graphs with no modification, eventually leading to an entire specification. Furthermore, path constraints and path coverage can be set across large graphs, enabling larger specification to be used to generate specific tests for scenarios. This flexibility makes PSS ideal for bottom-up scenario application, top-down executable intent specification, and incremental test production.
Horizontal Reuse
Being able to perform functional verification across the entire design flow requires a second form of reuse, something often referred to as horizontal reuse. This name is confusing as it implies the same kind of reuse as the badly named Portable Stimulus. The only thing that is reused is the design integrity model.
Verification synthesis consists of two stages. The front end, the part that tool vendors talk about, is the creation of a path through the model that adheres to user constraints and preferences.
Once that scenario is defined the execution platform is targeted. This itself consists of two noteworthy pieces. One comes from the vendor and the other from the user.
The vendor piece establishes a testbench mechanism. As a simple example, a simulator provides procedural interfaces that enable almost anything in the design model to be accessed or manipulated. Capabilities such as backdoor memory access allow information to flow that bypasses debug mechanisms or to enable actions to be performed that look as if they take zero time compared to other activities that pass through the design. Try doing that on real silicon!
To enable real silicon to participate in functional verification requires that some of these capabilities are implemented. To access or modify memory contents, code runs on an application processor within the design that has access to the necessary memory. It could read or write data and feed it out on a UART port.

Most test scenarios will be a combination of code that executes on the embedded processors and stimulus that is injected into the primary ports of the design. Scenarios are constructed that know how these things need to be synchronized. This requires the vendor to provide a toolbox for this kind of activity to be coordinated.
The second piece required for reuse is contained within each of the models. Once the mechanisms for a particular target have been built, the model has to inform the generator what has to be done in order to make each action happen. For example, if it is a DMA action, the current address and target address have to be defined, the size of the transfer and potentially other configuration information established. How this is performed is dependent upon the target platform and the testbench infrastructure that has been provided.
Horizontal reuse doesn’t just happen. It is planned and takes significant user and vendor code to make it happen. This means that each vendor may have different levels of support for each target.
Lest I forget, it is not portable stimulus, but portable verification and that requires getting results back from the target platform. This may differentiate tools from different vendors. For example, an emulator is at its peak efficiency when it can run for long periods without interacting with the outside world which would slow it down. Result information or even stimulus may benefit from being buffered and the transfer of data performed in a burst manner once the emulator has been stopped. These capabilities are defined by the tool vendor. Thus, the PSS tool can impact the efficiency of the target.
Arguments can be made that this would benefit the emulation vendor that can do special optimization that is not made available to others. However, there are likely to be multiple engines in a complete verification flow and the efficiency of the testcases is probably more important overall. Independent companies also may get better access to a variety of targets provided by several vendors rather than concentrating only on internal engines.
Getting Started
Portable Stimulus tool vendors can do plenty to help users become productive in a short space of time. Some are obvious, such as help learning the language. In addition to training, the way in which models are entered can help. For example, while PSS is a textual standard, users often comprehend a model better by being able to see it pictorially. In the early days, they may also benefit from being able to create it using a graphical editor. Ultimately, experienced users almost certainly revert to textual means, but graphics can help.

Perhaps, even more helpful are complete working examples. Simple examples are great in documentation and whitepapers as they provide a step-by-step guide through code snippets and explain some of the details about language constructs. Vendors may even provide the complete code necessary to rerun those examples.
Some problems come up frequently. Consider for example, the number of companies that start with an ARM core cluster that may have cache coherency between them and allow for the integration of other components. That cluster can then be integrated into an SoC. How do users ensure that coherence has been preserved? To do that, they need to be able to generate suitable tests that will stress the system.
It is unreasonable to require that every company develop the necessary models themselves. That is where the notion of “Apps” comes in. Apps are pre-developed, configurable models that solve a general problem and can be deployed out of the box, sometimes with only a small amount of configuration.
Another aspect to this already mentioned are libraries of functions that enable models to be built faster and in a more robust fashion. The HSI interface and foundation library are an example. Users can quickly integrate these functions with all of the extensibility built into them now and into the future.

In addition to the advantages already discussed that result from adoption of graph-based verification methodologies, they have a significant impact on other aspects of the verification flow. These on their own could provide enough incentive for many users to make the switch.
Debug accounts for more than 40% of total time spent by design and verification engineers. If that could be reduced by a significant amount, the time saving translates directly into increased productivity. One of the big problems with UVM is that users have no idea what each test generated by the solver actually does. It is random, but random in the wrong ways.
When a test fails, the first thing to be done, in many cases, is to work out what the test is doing. That may provide guidance for working out if there is a design error, such as whether the test created is legal. If not, constraints have to be modified to make sure that test is not be generated in the future, a step that often needs debugging because errors in constraints are common. Or, if the specification was unclear, it may result in a design change, testbench change or both.
Another problem with UVM verification flows is that users have to wait for an effect of a bug to be propagated to a checker, which probably resides on the exterior of the DUT. That may be many clock cycles after the bug actually happened. Back-tracking through a design is time consuming and tedious.
With graph-based solvers, tools display exactly what a test is doing. It can identify the path taken through the design, display the schedule created for various tasks assigned to blocks in the design, and show the first point in the execution of the test that failed. Users are closer to the source of the bug and have things to help them understand the context of the problem.
This reduces debug time and uncertainty, the bane of project scheduling. The time taken to fix problems, once found, may still be an unknown, but the uncertainty will be removed from the process.
When UVM was introduced, it was touted as a tool that would enable users to quickly build coverage. Vendors admitted that this productivity would level off and the last few percent would take longer to find. As designs became more complex, that leveling off starts to happen sooner and closing the coverage gap can be difficult without resorting to manual test creation.
The creation of the coverage model has become one of the harder aspects of verification, and closure the most problematic. Within UVM, there are no functional links between stimulus creation, scoreboards and checkers, coverage, or constraints. Because of this, getting stimulus generators to target coverage holes is difficult. Functional coverage is a proxy for RTL implementation coverage, based on observations from within the design that infer certain functionality is being executed. It does not guarantee that, when executed, it functions correctly and that any error generated has been propagated and verified on an output pin.
Graph-based techniques add a new form of coverage that comes directly from the graph. It tells users exactly what functionality has been verified and the execution of each test fully checked, making coverage based on the graph a true act of verification.
Does this mean that users will never write another coverage model? Users may want to continue to do that.
Functional coverage tells users about what has happened in the implementation. They may want that to show if there are deficiencies in the testbench. Remember, an act of verification requires that two models are compared and the differences between them found. If users only rely on coverage coming from the verification environment, they may not identify parts of the implementation that have not been exercised. This could indicate a missing node in the graph, functionality in the design not reachable or meant to be there.
Thank you for reading the piece. It is a complicated subject. I recognize my analysis is incomplete. It is meant to understand the opportunity from an investment point of view and what it would take to bring a solution to market that would benefit the consumer. I welcome any feedback and additions.
Jim Hogan, Vista Ventures LLC.
Santa Cruz, California




Consolidation and Competition: Who is Winning the $4.5 Billion Interface IP Race?