

It seems like I have written a lot about SRAM lately. Let’s face it SRAM is important – it often represents large percentages of the area on SOC’s. As such, SRAM yield plays a major role in determining overall chip yields. SRAM is vulnerable to defect related failures, which unlike variation effects are not Gaussian in nature. Fabrication defects are discrete events and random in nature. As a consequence of this they follow Poisson distributions. So, modeling them is distinctly different than things like process tilt or variation. While, as is the case with other parts of the design, modeling is important, it is especially important for SRAM. If there is a likelihood of a failure, replacement SRAM units can be allocated to serve in its stead.

But how much redundancy should be provisioned? If none is provided, a single failure will render the chip useless. This is in effect will double the cost of the part – a new part is needed to replace the failed device. At the other extreme, if 100% redundancy is provided, we again are looking at nearly double the cost per part. So, where is the happy medium?
The rate of failures depends on what happens in so called Critical Areas – where defects that are known and their rate is established, can cause failures. The presence of a failure depends on the size of the defect. Some are too small to cause harm, others are so massive that they render the entire chip inoperative. Usually the foundry as extensive data on the kinds and sizes of defects that cause recoverable issues with SRAM.
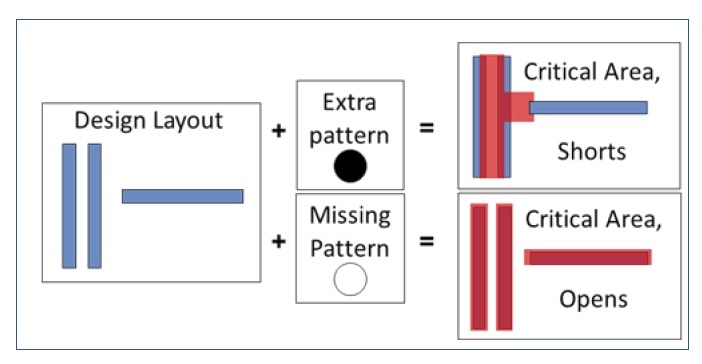
Of course, if we are talking about a defect that causes a power to ground short or a malfunction in a sense amp, we are going to have a hard time managing that. For the other class of failures – a row or column failure, alternative resources can be mapped to take their place. A great many papers have been written on techniques for implementing these replacements. However, design teams still faces a judgement call as to just how much redundancy to implement.
Fortunately, Mentor offers an option in Calibre called the YieldAnalyzer tool that can help translate defect density data into yield projections for a specific design. It starts by taking the defect density information for each layer to calculate the average number of failures. Calibre YieldAnalyzer uses yield models to then calculate yield. There are special cases, such as vias, where a single defect may not alter connectivity due to the large number of duplicate elements in a structure like a via array.
Calibre YieldAnalyzer must also be aware of the specific defects associated with row or column failures for each memory block. This is usually layer dependent, and is specified in a configuration file. The tool uses information on available repair resources. Of course, these resources are also subject to failures, so a second order calculation is needed to determine the availability of the actually functioning repair resources.

Because of how Calibre YieldAnalyzer works, it is possible to easily perform what-if analysis to zero in on the optimal amount if repair resources. As was mentioned at the outset, due to the large area of SRAM and the expense of adding repair resources, it is desirable to find the optimal balance between too many and too few.
It’s easy to think of Calibre as a rule checking program, however its capabilities have expanded well into the area of DFM. Helping to provide assistance with optimizing repair resources goes way beyond physical checking and encompasses sophisticated statistical analysis. Mentor has a white paper on their website that goes into much more detail about the process and algorithms used to provide these results.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.