





Naveen Verma, Ph.D., is the CEO and Co-founder of EnCharge AI, the only company to have developed robust and scalable analog in-memory computing technology essential for advanced AI deployments, from edge to cloud. Dr. Verma co-founded EnCharge AI in 2022, building on six years of research and five generations of prototypes … Read More
Podcast EP295: How Nordic Semiconductor Enables World-Class Wireless Products with Sam Presley
Dan is joined by Sam Presley, technical product manager at Nordic Semiconductor. With a background in electronics engineering, embedded firmware development and consumer products development, his current areas of expertise are hardware and software for IoT applications, with a special focus on enabling product manufacturers… Read More





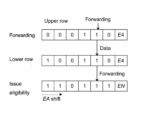


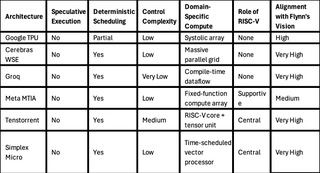
Flynn Was Right: How a 2003 Warning Foretold Today’s Architectural Pivot