

5G is already real, though some of us are wondering why our phone connections aren’t faster. That perspective misses the real intent of 5G – to extend high throughput (and low latency) communication to a vast number and variety of edge devices beyond our phones. One notable application is Fixed Wireless Access (FWA), promising to replace fiber with wireless broadband for last mile connectivity. Consumers are already cutting their (phone) landlines; with FWA they may also be able to cut their cable connections. Businesses can take this further, installing FWA base stations around factories, offices, hospitals, etc., to support many more smart devices in the enterprise.
An essential business requirement to enable this level of scale-out is much more cost-effective wireless network infrastructure. Open Radio Access Network (Open RAN) and virtualized RAN (vRAN) are two complementary efforts to support this objective. Open RAN standardizes interfaces across the network, encouraging competition between network component suppliers. vRAN improves throughput within a component by more efficiently exploiting a fixed hardware resource for multiple independent channels. We know how to do this with standard multi-core processor platforms, through dispatching tasks to separate cores or through multi-threading. Important functions in the RAN now run on DSPs, which also support multi-core but not multi-threading. Is DSP innovation possible to overcome this drawback?
What’s the solution?
Existing RAN infrastructure components – specifically processors used in baseband and backhaul– support virtualization / multithreading and are well established for 4G and early 5G. Surely network operators should stick to tried-and-true solutions for Open RAN and vRAN?
Unfortunately, existing components are not going to work as well for the scale-out we need for full 5G. They are expensive, power hungry (hurting operating cost), competition in components is very limited, and these devices are not optimized for the signal processing aspects of the RAN. Operators and equipment makers have enthusiastically switched to DSP-based ASICs to overcome those issues, especially as they get closer to the radio interface and user equipment, where the RAN must offer massive MIMO support.
A better solution would be to continue to leverage the demonstrated advantages of DSP-based platforms, where appropriate, while innovating to manage increasing high-volume traffic more efficiently in a fixed DSP footprint.
Higher throughput, less DSPs
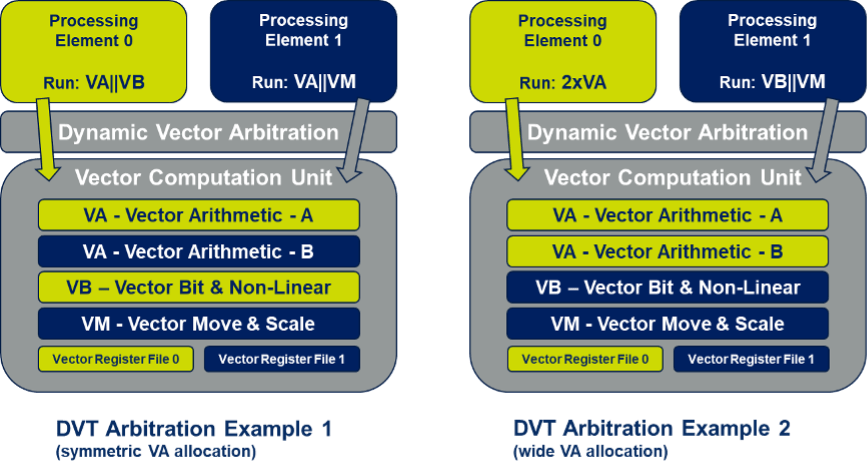
Multi-core DSP system are already available. But any one of those DSP cores is handling just one channel at a time. A more efficient solution would also allow for multi-threading within a core. Commonly, it is possible to split a core to handle two or more channels at one time, but this fixed threading is a static assignment. What limits more flexibility is the vector compute unit (VCU) in each DSP core. VCUs are major differentiators between DSPs and general-purpose CPUs, handling all the signal-intensive computation – beamforming, FFT, channel aggregation and much more – in the RAN processing path between infrastructure and edge devices. VCUs consume significant footprint in DSP cores, an important consideration in multi-core systems during times when software is executing scalar operations and the VCU must idle.
Utilization can be improved significantly through the dynamic vector threading architecture illustrated in the figure above. Within one DSP core, two scalar processors support 2 channels in parallel; this does not add significantly to the footprint. The VCU is common to both processors and provides vector compute functions and a vector register file for each channel. So far this looks like the static split solution described earlier. However, when only one channel needs vector computation at a given time, that calculation can span across both compute units and register files, doubling throughput for that channel. This is dynamic vector threading, allowing two channels to use vector resource in parallel when needed, or allowing one channel to process a double-wide vector with higher effective throughput when vector need on the other channel is inactive. Naturally the solution can be extended to more than two threads with obvious hardware extensions.
Bottom line, such a system can both process with multiple cores and dynamically multi-thread vector compute within each core. At absolute peak load the system will still deliver effective throughput. During more common sub-peak loads it will deliver higher throughput for a fixed number of cores than a traditional multi-core system. Network operators, businesses and consumers will be able to get more out of installed hardware for longer, before needing to upgrade.
Talk to CEVA
CEVA have been working for many years with the big names in infrastructure hardware, consumer and business edge products. They tell me they have been actively guided by those customers towards this vector multi-threading capability, suggesting dynamic vector threading is likely to debut in products within the next few years. You can learn more about CEVA’s XC-20 family architecture offering dynamic vector threading HERE.
Share this post via:



Silicon Insurance: Why eFPGA is Cheaper Than a Respin — and Why It Matters in the Intel 18A Era