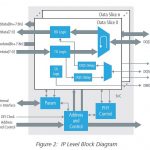
Ever since I have seen Atrenta’s SpyGlass platform providing a comprehensive set of tools across the semiconductor design paradigm, I felt the need for a common set of standards to evolve for sign-off at RTL level. Last December, when I read an EE Times articleof Piyush Sancheti, VP, Product Marketing at Atrenta, where he talks about a billion gate SoC design, shrinking market windows, and design cycles to the level of 3-6 months, I was looking for an opportunity to talk to him in a broader sense on how RTL level design paradigm is proliferating and what we can see in future. This week I had a nice opportunity talking to him face-to-face in Atrenta’s Noida office. Here is the conversation –
Q: SpyGlass is primarily providing a platform for designs at RTL and for sign-off at that stage. What has been your experience so far?
In today’s SoC design environment, you have size, scale and complexity of advanced nodes being the prime factors. Most of the SoCs use several soft IPs, configurable at different levels, and some hard IPs as well. Iterative design closures do not serve the purpose for such large designs. Add to it very short market windows; there is another level of market segment coming up for Internet-of-Things, that has very short turn-around-time in the order of 3 months. RTL sign-off has become a need today to answer this faster design closure with lesser cost.
So, to answer in short, our leading edge customers are executing on RTL sign-off and are happy to see the value in it. Last year was the best year for us in terms of business and growth and we are looking at a bright future from here.
Q: Considering the amount of IP re-use and sourcing from third party for SoC design, a standard RTL sign-off criteria can help in reliable IP exchange as most of the IPs are sourced at RTL level. Your comments?
Yes, definitely, at the top level an SoC can have just connectivity between many IPs connected through glue logic. So, quality of the SoC will depend on the quality of IPs and therefore a standard criterion must be there for IPs, internal or external. We have been working with TSMCon a standard for soft IP qualification.
Q: That’s quite encouraging. Looking at your talk in EE Times about billion gate SoCs becoming a reality, I can definitely see that RTL sign-off is a must. But do you see common standard RTL sign-off criteria or rather RTL coverage factors evolving across the industry for the overall semiconductor design?
Yes, it’s required. Even if all IPs on an SoC are qualified, it doesn’t guarantee the quality of the SoC. What if there is a clocking scheme mismatch between IPs? Even at the connectivity level between IPs, we need to look at the common plane issues, consistency, synchronous versus asynchronous and the like. So, a standard at SoC level sign-off is again a must for the industry. And we are working at it, along with some of our leading customers; it depends on a majority of the design houses adopting this path. It will take time to break that inertia; people will realize that this change in methodology is needed when they are no longer able to continue with the same old methodology.
We have talked about the problems so far, let’s talk about some solutions. We now offer a smart abstract model concept for blocks in SoC design. RTL sign-off can be done at a hierarchical level; this has very fast turnaround. This is now in use in some of the most complex SoC designs with multiple levels of hierarchy. We have seen amazing results in performance, capacity, memory utilization, number of violations etc. We are talking gains that are in one or two orders of magnitude. So, we definitely would be interested in evolving the common standard for SoC sign-off at RTL.
Q: What all should get covered in RTL sign-off?
It’s across various design domains; clocking, testability, physical, timing, area, and power. Rules to avoid congestion and ensure routing completion such as fan-in, fan-out, mux sizes and cell pin density. On the timing side, there is logic depth, CDC, clock gating etc. Similarly there are rules for power and area. We have about 300 rules of the first order. These have broad applicability across a wide range of the market segments.
Q: RTL sign-off is a must at the beginning of an SoC design and a post layout sign-off at the end. Do you see the need for any intermediate level of sign-off such as post floorplan level?
Yes, SoC design needs a continuous monitoring at each stage. Quality and sign-off is a culture which must be exercised at each stage as the SoC passes through the design phases such as floorplan, placement and so on. By doing sign-off at RTL, one can get to design closure much faster, more productively and at lesser cost. As we pass through lower levels of design, the cost and iteration time increases. The other advantage at RTL signoff is that it minimizes iterations at lower levels. Overall it can reduce the design schedule risk by 30-50%.
Q: Do you see a possibility of leading organizations working at RTL, joining together to define a common standard for RTL sign-off of IPs and SoCs for the semiconductor industry? Can Atrenta take a lead? Who should own the standard?
As I said earlier, we are already working with TSMCand some of our other leading customers on this. We would be very interested in a common standard evolution which can benefit the whole semiconductor design industry. However, it needs about 10-12 major players from the design community, foundry and EDA to get the ball rolling. Eventually it will become a success only when majority of the semiconductor design community embraces it, as we have seen in other spaces. At this moment, we are not limited by capability; we are limited by the number of users which need to be large enough to provide that kind of momentum.
So, yes we can give it a start, mature it, but going forward some standard body should own it. It may be a new standard body or any of the existing one, we have to see.
Q: How far from now do you see that standard evolving?
I guess it should take minimum 18-24 months from now. It will not fly until we have a critical mass of the community starting to use it.
I felt extremely happy after talking to Piyush, especially on learning that what I was thinking is already in progress. This was one of my best conversations with industry leads. I really admire Piyush’s thought process when he said, “we are not doing it on our own. We continuously learn from our customers and partners who provide us the right direction to do things better in this challenging environment and change the ways that can lead to better productivity.” Let’s watch what’s there in store for future.
More Articles by Pawan Fangaria…..
lang: en_US