Both Altera and Xilinx are innovative companies with robust ecosystems, right? It would be a terrible shame if you located the perfect FPGA IP block for a design, but couldn’t use it because it was in the “wrong” format for your preferred FPGA. What if there were a way around that?
There is a compelling argument to use each FPGA vendor’s tool that delivers synthesis results optimized for their particular FPGA. However, that can be a limiting factor in a design with numerous IP blocks. Constraining the IP search to only the FPGA’s vendor ecosystem may artificially rule out what might be the best option for differentiating a design. Imagine what would happen if your firm is looking at acquiring another firm, and you discover they work in the other FPGA environment. “Oh, dang it, we can’t buy them ….” Probably not a good response.
It makes a lot more sense to be ready for any FPGA IP that comes your way. I’d also like to challenge the assumption that a third-party FPGA synthesis tool can’t deliver the same or better quality of results – QoR is a function of the entire design, after all the IP is comprehended. Synopsys Synplify Premier is designed to handle both Altera and Xilinx IP, working with the various formats and constraints, and deliver better synthesis results.
Paul Owens, Sr. Corporate Applications Engineer for Synopsys, points out in a recent webinar that there are two broad categories of FPGA IP: interface, and datapath. Interface IP often has vendor-specific physical constraints and non-timing constraints, while datapath IP has associated timing constraints. There is also the possibility that vendor IP is in one of several formats. Life is good if everything is in readable RTL source, but Altera IP is often encrypted RTL, and Xilinx IP also comes in DCP (Design Check Point) and BD (Block Design) formats.
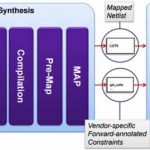
Readable RTL can be added in what Owens calls absorb mode. The entire IP is read in, the synthesis engine gets to optimize timing paths and logic in and around the IP, and the final netlist contains the IP netlist in entirety.
What if IP is encrypted? Synplify Premier also handles a white or grey box method. Timing models for the IP are read in, and the synthesis engine optimizes around it but doesn’t modify the IP itself. These IP blocks typically have more complex constraints, which Synplify Premier imports for synthesis of surrounding logic while preserving the original constraints for place & route of the encrypted block.
Constraints can make or break a synthesis cycle. Writing and importing constraints is a hugely important step in achieving QoR. About half of Owens’ presentation is devoted to dealing with constraints and achieving QoR, even while working with the disparate IP types. A noteworthy observation is Synplify Premier works with the Xilinx Vivado place & route engine for congestion improvement, and similar capability is in development for Altera.
This webinar provides one of the most packed yet to-the-point descriptions of Synplify Premier capability I’ve seen. Owens discusses the benefits of parallel place & route on a server farm, which can significantly speed up the overall synthesis process. He also touches on the debug process with the Identify debugger, offering a unified environment and one look and feel regardless of which side the FPGA IP came from.
To view the entire webinar (registration at TechOnline):
Accelerate your FPGA Design Schedules with Synplify Premier
I’ve called the concept of free the “f-word” of technology marketing: operating systems, EDA tools, it’s all the same argument. There are times in more advanced scenarios where paying for a tool delivers better results. FPGA synthesis on big projects with disparate IP and complex constraints is one of those scenarios where productivity and QoR gains are worth the investment in a tool like Synopsys Synplify Premier.