SuperSpeed USB specification was released in November 2008! Even if we can see USB 3.0 powered peripherals shipping now, essentially external HDD, connected to PC equipped with Host Bus Adaptors (as PC chipset from Intel or AMD were not supporting USB 3.0), it will take up to the second quarter of 2012 before PC will be shipped with “native” USB 3.0 support; native just means that PC chipset will integrate SuperSpeed USB. This will be the key enabler for USB 3.0 wide adoption in PC & Media Tablet, Smartphone and many consumer electonic applications.
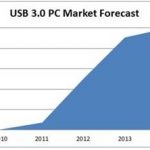
It will have taken more than three years to Intel –and AMD- to finally support USB 3.0 technology. If we trust InStat, it will only take two years before more than 90% of PC being shipped natively support this technology, see the figure:
This short reminder to help the reader understand the importance of Synopsys’s Press Release about the explosion of the Design-in for SuperSpeed USB IP. Synopsys USB Marketing manager Eric Huang is claiming 40 sales since USB 3.0 IP product launch, in 2009, and we think, first that this is true, and second that 25 sales have been made in 2011 only.
Some more history: Synopsys was already the USB IP market leader with more than 60% market share when they bought ChipIdea from MIPS, to get a more than 80% market share at the time where the USB IP market was only made of High Speed (2.0), Full Speed and Low Speed. When SuperSpeed USB was released, the backward compatibility constraint imposes to provide both USB 2.0 and USB 3.0 function to be 100% compatible. IP vendors previously active in the USB 2.0 market had disappear (except Faraday) and the new comers, able to easily manage the design of a 5 Gbps SerDes to build the USB 3.0 PHY were missing the “stupid” 480 Mbps PHY you need to provide in order to be fully compatible…
Then Synopsys has been in a very good position to capitalize on the existing USB port-folio and experience, develop SuperSpeed USB PHY and Controller and integrate all the pieces to build a complete, 100% USB 3.0 compatible solution. The testimonial from Realtek highlights how important was Synopsys’s track record in USB 2.0 to support their selection for USB 3.0:
“We taped-out Synopsys’ DesignWare USB 3.0 host and USB 3.0 device in three chips targeted at the digital home and PC peripheral markets, and all are now shipping in mass production,” said Jessy Chen, executive vice president of Realtek Semiconductor Corporation. “We chose Synopsys DesignWare IP because of the company’s excellent track record in USB 2.0. With Synopsys’ USB 3.0 IP now fully certified and proven in our chips, we are certain we picked the right IP partner. We have been at the forefront of USB 3.0 development and integration, and have many innovative chips using Synopsys USB 3.0 IP coming in 2012.”
Very important for today’ SoC designs is the capability offered by the IP vendor to support the validation: of the function (IP), of the chip prior to mask generation and of the Software as early as possible in the product development cycle, to speed-up Time-To-Market and guarantee first pass success. This is possible when the following boxes are ticked:
- Verification IP available at the same time than the IP
- Especially important for a standard based protocol, IP certification obtained
- In order to validate the Software as early as possible, in parallel with the SoC development, availability of FPGA-based prototype solution, HAPS, as stated by DisplayLink:
“Working with Synopsys for our USB 3.0 controller, HDMI controller and PHY IP helped us mitigate our project risk and reach volume production with our first-pass silicon,” said Jonathan Jeacocke, vice president of engineering at DisplayLink. “In addition, we used Synopsys’ HAPS® FPGA-based prototyping solution to build fully functional systems for at-speed testing of USB 3.0 and HDMI, including architecture validation, performance testing, software development and customer demonstrations.”
Some precision about these HAPS boards:
· 2 PCs are connected to a HAPS FPGA-based Prototyping platform
· The HAPS on the left has Synopsys USB 3.0 Host with a Synopsys USB 3.0 PHY daughter card.
· The HAPS platform on the right has Synopsys USB 3.0 Device, also with the Synopsys USB 3.0 PHY daughter Card.
· This is also connected via PCIe (using Synopsys PCIe) to a PC running Linux drivers for the Device.
The HAPS boards and PHY boards are off-the shelf from Synopsys, and the USB 3.0 Host, USB 3.0 Device and PCIe cores are from Synopsys.
If we look at the market segment where USB 3.0 adoption will come first “In-Stat expects several hundred million USB 3.0-enabled devices will ship in 2012, including a large share of tablets, mobile and desktop PCs, external hard drives and flash drives,” said Brian O’Rourke, research director at In-Stat. “By 2014, we expect many consumer electronics devices to transition to USB 3.0, including digital cameras, mobile phones and digital televisions. Overall, in 2014, we forecast that 1.4 billion USB 3.0 devices will ship. IP suppliers like Synopsys will help fuel this explosion in USB 3.0 adoption.”
I fully agree with the forecast mentioning several hundred million USB 3.0-enabled devices will ship in 2012, I just would like to precise that external hard drives proposed today to consumers are already USB 3.0-enabled, now in 2011. Moreover, IPNEST don’t think we will have to wait until 2014 to see Smartphone supporting USB 3.0, and we will probably see these devices on the market before, or at the same time than Media Tablet, as more than 60% of Media Tablet are using the same Application processor than Smartphone.
Then there will be a second wave of consumer electronics devices to transition, namely the Digital TV, Set-Top-Box, Blue Ray Players, to ship in 2012-2013, followed by Digital Video camera and Digital Still cameras. This means IP sales starting now and continuing in 2012 to allow for a minimum development time. In fact we have built a forecast for USB 3.0 IP sales based on a bottom-up analysis, looking at the different application in every market segment which could transition to USB 3.0, and even more important, we have tried to determine when the IP sales will happen, application by application. The result is a very complete 50 pages document, where you can find many useful informations, like the design start evaluation (generating USB 3.0 IP sales) up to 2015:
Eric Esteve from IPNEST
– Table of Content for “USB 3.0 IP Forecast 2011-2015” available here