
This is it! This is the single page of code that Ákos Hadnagy wrote this summer to formally verify WARP-V, an open-source RISC-V CPU core.
I’ve been told the average software developer writes just five lines of code per day. As my mentee this summer in Google Summer of Code, Ákos wrote much less. You might think, as his mentor, I wouldn’t be too happy about this. But I am happy. I’m ecstatic! Had he written 20K lines of code, no one would care about his work. CODE IS BAD! It carries bugs. You write it because you have to in order to get stuff done, and Ákos got a lot done with this little bit of code. He formally verified not just a single CPU core, but a whole family of them. And that’s why, between exams, you can find Ákos presenting his work at conferences like ORConf (video) and VSDOpen.
In this post, I’ll explain the magic behind this page of code–a page which corresponds to 20(!!!) in SystemVerilog. That’s for one particular implementation. This page of code results in unique SystemVerilog code for any number of different configurations of WARP-V! I guess, in a sense, Ákos did write more than five lines per day.
The Origins of Yet Another RISC-V
I am the proud founder of Redwood EDA. We’re the guys behind makerchip.com. Our attention is focused on Transaction-Level Verilog (TL-Verilog), the technology that makes this work possible. It’s a follow-on to SystemVerilog that represents a giant leap forward in both simplicity and capability. It’s a refreshing change of scenery in a domain that has essentially lain dormant for the past 30 years.
Back in December (2017), I needed a good showcase for TL-Verilog. So I put together a RISC-V model, and I scrambled for the Jan. 15 submission deadline for DAC (the Design Automation Conference). I’ve never gotten anything accepted into a conference before based on a week and a half of work, but everyone loves RISC-V, and the fact that I could implement one in a week and a half was kinda the point. And, as I mentioned, it wasn’t just a single CPU core implementation, it was a flexible CPU core generator. More flexible than any other I’ve been able to find. That was also the point. Startups have been funded with less to show. (My slides from DAC are here: “Overcoming RTL: The Most-Adaptable Open-Source RISC-V Core.”)
Ákos’s work this summer takes this showcase to the next level, showing that TL-Verilog isn’t only beneficial for flexible modeling of logic; it’s also great for flexible verification modeling.
WARP-V
Let’s take a quick look at the design. The microarchitecture of WARP-V is nothing special. It’s pretty much straight from any college textbook. CPU design was my career, and I find it amusing that technology scaling trends and power are driving us back to these simple cores. But I digress. Here’s a high-level block diagram of WARP-V:
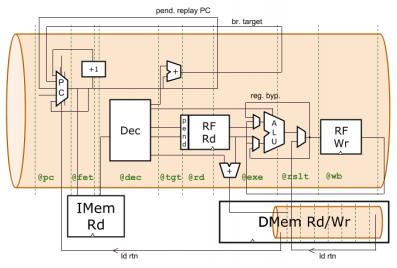
What’s most unique about WARP-V is its flexible pipeline. The stages labeled in green are actually “virtual pipeline stages.” A specific implementation can control the depth of the pipeline by mapping these virtual stages into physical ones. In RISC-V, decode is very simple, so we might want decode, branch target calculation, and register read to all be done in the same stage. So we map the virtual stages @dec, @tgt, and @rd to the same physical stage. Finer-grained tweaks can be made safely with minor code changes. TL-Verilog tools turn this partitioned logic into RTL, providing the necessary flip-flops and staged signals to implement the pipeline. At a faster frequency, or for a different ISA we might choose, instead, to stretch this logic across different stages. Oh, right, yes I did say, “for a different ISA.” Yeah, you can do that. That’s another unique thing about WARP-V, enabled by TL-Verilog, but let’s not confuse matters with that.
Formal First
Now, lest you get the wrong impression, Ákos wasn’t just twiddling his thumbs all summer, writing half a line of code each day. He was helping to transform my slapped-together demonstration into a robust design. And to do that, we skipped traditional simulation altogether and jumped straight to formal verification, specifically, bounded model checking. In fairness, there’s more than a page of code involved here, but we didn’t have to write most of it. Ákos used an infrastructure called riscv-formal. This is from an amazing guy named Clifford Wolf, who is nearly single-handedly driving a revolution toward open-source EDA.
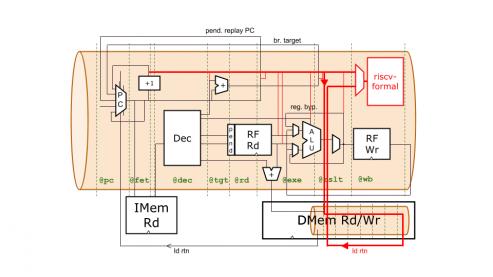
Riscv-formal provides the checkers to ensure conformance to the RISC-V ISA. It is depicted by the red box in the diagram. Heading into this box is the complete characterization of each retiring instruction.
Ákos’s one page of code is the verification harness that provides this input. It collects together information about each instruction from signals that exist in different stages of the flexible pipeline. Signals must be staged the proper number of times to align them for the checks. (This staging is represented by the upper red path in the diagram.) In RTL, the staging of these signals is significant and leaves plenty of room for error, especially when the pipeline is changed and the staging must be changed to match. Here, TL-Verilog tools manage this staging. All that is left to provide is the hookup to the riscv-formal checks through a small amount of combinational logic to present the inputs in their expected form. Simply using a signal in this hookup is enough to pull it through the pipeline. The pipeline can be adjusted all you like, and the verification harness doesn’t change at all!
A Headache Averted–Loads
But I’ve glossed over a wrinkle here. There’s a big red loop in the diagram through the memory that I haven’t explained. This is for load instructions, which are a bit problematic. Loads go off to memory and take as long as they need to find their data and return it to the core (though the current memory implementation has a parameterized fixed latency). And we can’t present the load instruction to riscv-formal without the load data. While we wait for the data, other independent instructions in the shadow of the load are allowed to retire.
Fortunately, Clifford is a bright guy, so he built riscv-formal with the flexibility to accept instructions out of order. Instructions behind the load are presented to riscv-formal as they retire, and when the load returns, we present it. In order to present it, we need to have all of the signals to present. Either we store them somewhere while we wait for the load data, or we carry them along with the load as it goes to memory and back. Our approach is the latter. In RTL, dragging these signals around is a bug-prone pain-in-the-rear. You’ll see that in TL-Verilog, it’s practically free.
In RTL, your design is just a jumble of logic and wires. A TL-Verilog model has more structure. There’s a construct for a pipeline with stages. Instructions in WARP-V are “transactions” that traverse a CPU pipeline. But the transactions need not be confined to a single pipeline. For loads, in WARP-V, a “transaction flow” is defined from the CPU pipeline into the memory and back. Memory access happens along this flow, which is easily defined by the statements below. First, we feed the instruction in the CPU (|fetch) pipeline into the memory pipeline with this statement in the memory pipeline:
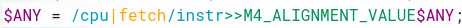
Then, from the end of the memory pipeline, we feed back into the CPU pipeline into a new context within the CPU pipeline, called /original_ld.

I won’t interpret every letter, but the point is it’s simple to define this transaction flow. And now, when load data returns into the CPU pipeline, we have direct access to any signals needed from the original load instruction that produced the data. (If I were at a podium, I would pause at this point to allow the significance of this to sink in.)
Let’s see how this is used in WARP-V. For the returning load, we must write the load data into the register file. To do this, we need the load data and the destination register index of the original load. We access these as /original_ld$ld_dataand /original_ld$dest_reg. As a result of these references, $ld_datais pulled from the memory pipeline, and $dest_reg is pulled the full way around the purple path shown below from the original load instruction. Just a few statements produce all the necessary flops and staged signals; our design is well organized and less likely to contain bugs; and the pipeline, er… pipelines, remain flexible.
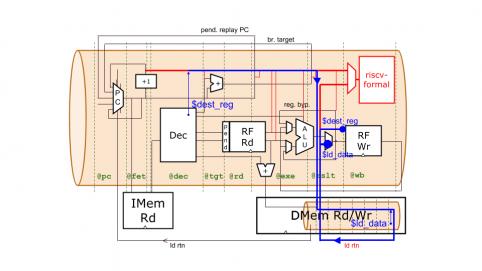
This same loopback flow that is valuable for the logic is even more valuable for the verification harness. While the design only needed two signals from this flow, the verification harness needs to present all information about the load instruction to riscv-formal via this flow. The first four lines of Ákos’s code (two of which only exist because of a current limitation in the tool) provide the MUX in red. (If you’d like a closer look, you can open the design. The harness is at the end.) The MUX output is the instruction presented to riscv-formal, either straight from the pipeline, or recirculated through memory for loads. The remaining code, once again, is just the hookup–purely combinational logic that sits at the input to riscv-formal. Any signals that are needed are pulled in automatically through the defined flow.
Well, that’s it. That’s the magic. Once you get it, RTL seems archaic. If I wasn’t clear or you’d like to try this for yourself, I’ve been busy putting together tutorials and other resources in Makerchip.
Wow. What’s Next?
Well, personally, I’ve got a hundred or so very exciting directions to go with this technology. I’m not sure how much of my focus will be on WARP-V going forward. There’s a business to be made out of it for sure, and if you say “RISC-V,” VCs will pop up, but for me, it’s likely to remain a showcase. I’ll probably make it into a multicore to show off transaction flows even more. There are several folks planning to explore the physical implementation, among other things. The license is permissive, so you’re free to do with it as you wish (but let’s collaborate). And, if you are a student, I expect there will be some great opportunities again in Google Summer of Code for 2019.
Here are some related links:
Ákos’s ORConf 2018 presentation video and slides
Our VSDOpen 2018 slides and paper, in case you want to see these benefits quantified
Clifford’s riscv-formal repo
The WARP-V repo:
My DAC 2018 slides
WARP-V in Makerchip:
Makerchip (for all things TL-Verilog):




Comments
There are no comments yet.
You must register or log in to view/post comments.