
 For many years TSMC has provided IC design implementation guidance as viewed from the process and manufacturing standpoints. The last time TSMC Reference Flow incremented, it was version 12.0 back in 2011. Since then, increased design, process and packaging related complexities of the advanced nodes have demanded more focused efforts –which have translated into incremental set of directives such as DPT (Dual Patterning Technology), advanced packaging CoWoS with HBM2, reliability analysis, EUV, etc.
For many years TSMC has provided IC design implementation guidance as viewed from the process and manufacturing standpoints. The last time TSMC Reference Flow incremented, it was version 12.0 back in 2011. Since then, increased design, process and packaging related complexities of the advanced nodes have demanded more focused efforts –which have translated into incremental set of directives such as DPT (Dual Patterning Technology), advanced packaging CoWoS with HBM2, reliability analysis, EUV, etc.
Advanced Nodes and Physical Design
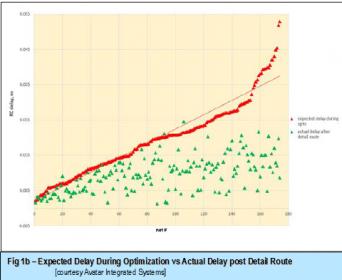 Finer geometry in advanced nodes has introduced timing degradation from wire and via resistance. The reference flow 12.0 recommends an enhanced routing methodology (such as by via count minimization, routing layers segregation and wire widening to mitigate the impact of wire and via resistance). Concurrently, there seems to be an increased in the EDA efforts to both tighten and secure timing optimization attained early (during synthesis/placement) with those of post-route stage. The heuristic nature and boundaries created by feed-forward point tools have partly contributed to the loss of predictability (figure 1a) and introduced a design capability gap, according to Prof. Andrew Khang from UCSD as seen in figure 1b.
Finer geometry in advanced nodes has introduced timing degradation from wire and via resistance. The reference flow 12.0 recommends an enhanced routing methodology (such as by via count minimization, routing layers segregation and wire widening to mitigate the impact of wire and via resistance). Concurrently, there seems to be an increased in the EDA efforts to both tighten and secure timing optimization attained early (during synthesis/placement) with those of post-route stage. The heuristic nature and boundaries created by feed-forward point tools have partly contributed to the loss of predictability (figure 1a) and introduced a design capability gap, according to Prof. Andrew Khang from UCSD as seen in figure 1b.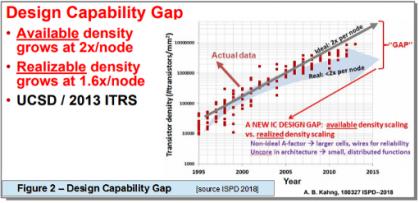
While many block level place and route tools have committed a shift-left move in order to account for numerous physical effects during placement ranging from the mainstream congestion-aware to more SI-aware, IR-aware, DRC-aware, etc., the complexity of the advanced node DRC rules are making the effort of producing a clean and optimal route more painful.
The original Avatar’s
Aprisa and Apogee are two products from Avatar Integrated Systems, a leading provider of physical design implementation solutions. Aprisa is a complete place-and-route (P&R) engine, including placement, clock tree synthesis, optimization, global routing and detailed routing. Its core technology evolves around its hierarchical database and common “analysis engines,” such as RC extraction, DRC engine, and a fast timer to solve complex timing issues associated with OCV, SI and MCMM analysis. Aprisa uses multi-threading and distributed processing technology to further speed up the process. The other product, Apogee is a full-featured, top-level physical implementation tool that includes prototyping, floor planning, and chip assembly –integrated with the unified hierarchical database. Its unique in-hierarchy-optimization (iHO) technology intended to close top-level timing during chip assembly through simultaneous optimization of design top and block levels.
Why a refresh needed

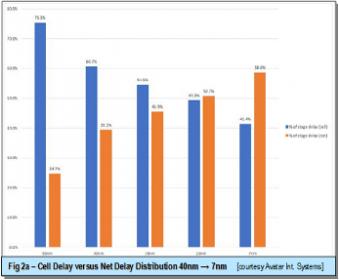
The performance impact of both wire and via resistance are more pronounced in sub-16nm process nodes. This can be seen by much narrower and longer routes due to a faster wire width shrink as compared to standard cell’s. Complex design rules is not helping redundant vias insertion either. As a result, the transition waveform shape is affected for both short and medium length routes. Furthermore, increased cross-coupling capacitance and net resistance simultaneously induced timing impact through larger crosstalk effects. In the end, wire delay takes an increasing percentage of cycle time. By 7nm process node, for nets of significant length, wire delay is measured as more than half of total stage delay and critical paths are much harder to close (as shown in figure 2a, 2b).
The conventional placement-centric place and route architecture methodologies with separate sequential flows are no longer adequate to address this interconnect related effects –as they cause significant pre-route versus post-route timing correlation issues, excessive design iterations, and suboptimal QoR.
Aprisa re-engineered for 7nm and beyond
During TSMC 2018 Open Innovation Platform in Santa Clara, Avatar has announced the availability of a new architecture to its Aprisa and Apogee solutions. With its breakthrough detailed-route-centric architecture addressing advanced nodes challenges, the new place-and-route provides > 2X faster design closure times with better QOR than the conventional counterparts.
As one of Avatar’s customers, Mellanox provides end-to-end Ethernet and InfiniBand intelligent interconnect solutions for servers, storage, and hyper-converged infrastructure. Their SoC designs have both unique characteristics and challenges, involving vast I/O interconnects fabric and utilizing advanced process nodes to reduce their switching latency.
“Advanced place-and-route technology is important for our silicon design activities as we move to more advanced processes,” said Freddy Gabbay, vice president of chip design at Mellanox Technologies. “The detailed-route-centric technology introduced with the new release of Aprisa consistently delivered better quality-of-results and predictable DRC and more than two times faster design time.”

Another customer, eSilicon, is a leading provider of semiconductor design and manufacturing solutions. eSilicon guides customers through silicon proven design flow, from concept to volume production. Its solution targeted for optimal PPA of ASIC/system-on-chip (SoC) design, custom IP and manufacturing solutions.
“eSilicon has used Aprisa on several very large and complex FinFET chips across several process nodes, including 16nm and 14nm,” said Sid Allman, vice president, design engineering at eSilicon. “We have successfully used Aprisa at both the block and top level with very good results. We expect to apply the new release to our advanced 7nm work as well.”
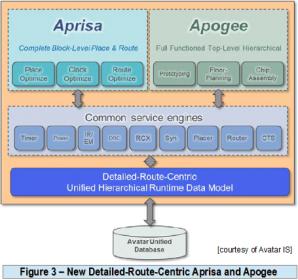 Avatar re-architected Aprisa and Apogee using three prong approaches as illustrated in figure 3:
Avatar re-architected Aprisa and Apogee using three prong approaches as illustrated in figure 3:
–Unified Data Model (UDM) is the single database architecture for placement, optimization, routing, and analysis. All Aprisa engines utilize the same data models, objects, and attributes in real time.
–Common Service Engine (CSE) enables analysis engines and optimization engines to work in concert. Any implementation engine can make dynamic real-time calls to analysis engines at will. Optimizations are made with accurate data the first time. Extraction and timing data gets updated dynamically and seamlessly.
–Route Service Engine (RSE) provides proper routing information on a per-net basis to any engine within the system that needs it. The RSE manages the route topology during all phases of optimization and reports to the calling optimization engine the net routing topology, such as metal layers used, RC parasitics and crosstalk delta delay.
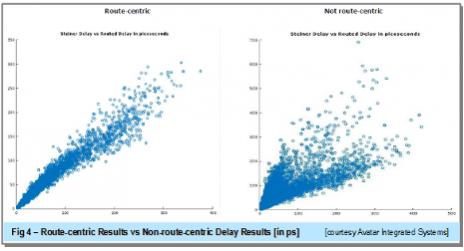
Only by predicting and guiding the route topology early in the design can optimization be performed effectively and efficiently as reflected in the results comparison with and without route-centric version in figure 4.
The new release also includes full 7nm support; IR-aware/hotspot avoidance; auto EM violation avoidance and fixing; native support of path-based analysis; design pessimism reduction and up to 20% power reduction.
“We are committed to developing new breakthrough technologies to address the most challenging designs in the industry,” said Dr. Ping-San Tzeng, Chief Technology Officer at Avatar Integrated Systems. “This breakthrough architecture to our flagship products provides leading design teams with much faster design closure while improving the quality of results at 16nm and below.”
To recap, it is imperative to have timing accuracy and predictability throughout placement and route to ensure timing closure convergence. Detailed-route-centric architecture in new Aprisa/Apogee coupled with unified data model and integrated optimization/analysis engines facilitates consistent and up-to-date optimization data throughout the flow, which helps deliver improved quality-of-results, reduces iterations and speeds design convergence more than 2X faster than competition.
Avatar will be highlighting Aprisa and Apogee’s new architecture at the Arm Techcon, October 16 – 18, 2018 at the San Jose Convention Center in booth #827.
Share this post via:



Chemical Origins of Environmental Modifications to MOR Lithographic Chemistry