
As AI and HPC systems scale to thousands of CPUs, GPUs, and accelerators, interconnect performance increasingly determines end-to-end efficiency. Training and inference pipelines rely on low-latency coordination, high-bandwidth memory transfers, and rapid communication across heterogeneous devices. With model sizes expanding and system topologies becoming more complex, the I/O fabric must match the pace of compute. PCIe remains the backbone of server connectivity, and with PCIe 6.0 operating at 64 GT/s and PCIe 7.0 at 128 GT/s, sustaining link utilization is now one of the central design challenges.
PCIe controllers built on a single-stream model cannot keep the link busy under modern AI traffic patterns. This is the motivation for the PCIe Multistream Architecture and was the topic of a recent webinar hosted by Synopsys. Diwakar Kumaraswamy, Senior Staff Technical Product Manager led the webinar session and provided some insights for Gen7 controller considerations too.
Why Multistream Architecture Is Needed
PCIe bandwidth has doubled with each generation, growing from 32 GT/s in Gen5 to 64 GT/s in Gen6 and 128 GT/s in Gen7. Gen8 is already under exploration at 256 GT/s. At these speeds, any idle cycle on the link produces a disproportionate bandwidth loss. AI workloads with their highly parallel, mixed-size transactions, amplify this issue. They generate a blend of large DMA transfers, cache reads, small control messages, and synchronization traffic, all arriving simultaneously from many agents.
Gen6’s shift to PAM4 signaling, mandatory FLIT encoding, and tighter latency budgets further stresses the controller. FLIT mode requires efficient packing of TLPs into 256-byte units, and the wider datapaths needed for PAM4 increase the amount of data the controller must handle each cycle. With only a single TLP accepted per cycle, the controller becomes the bottleneck long before the physical link is saturated. Multistream Architecture solves this by introducing parallelism in how transactions enter and flow through the controller.
How Multistream Architecture Works
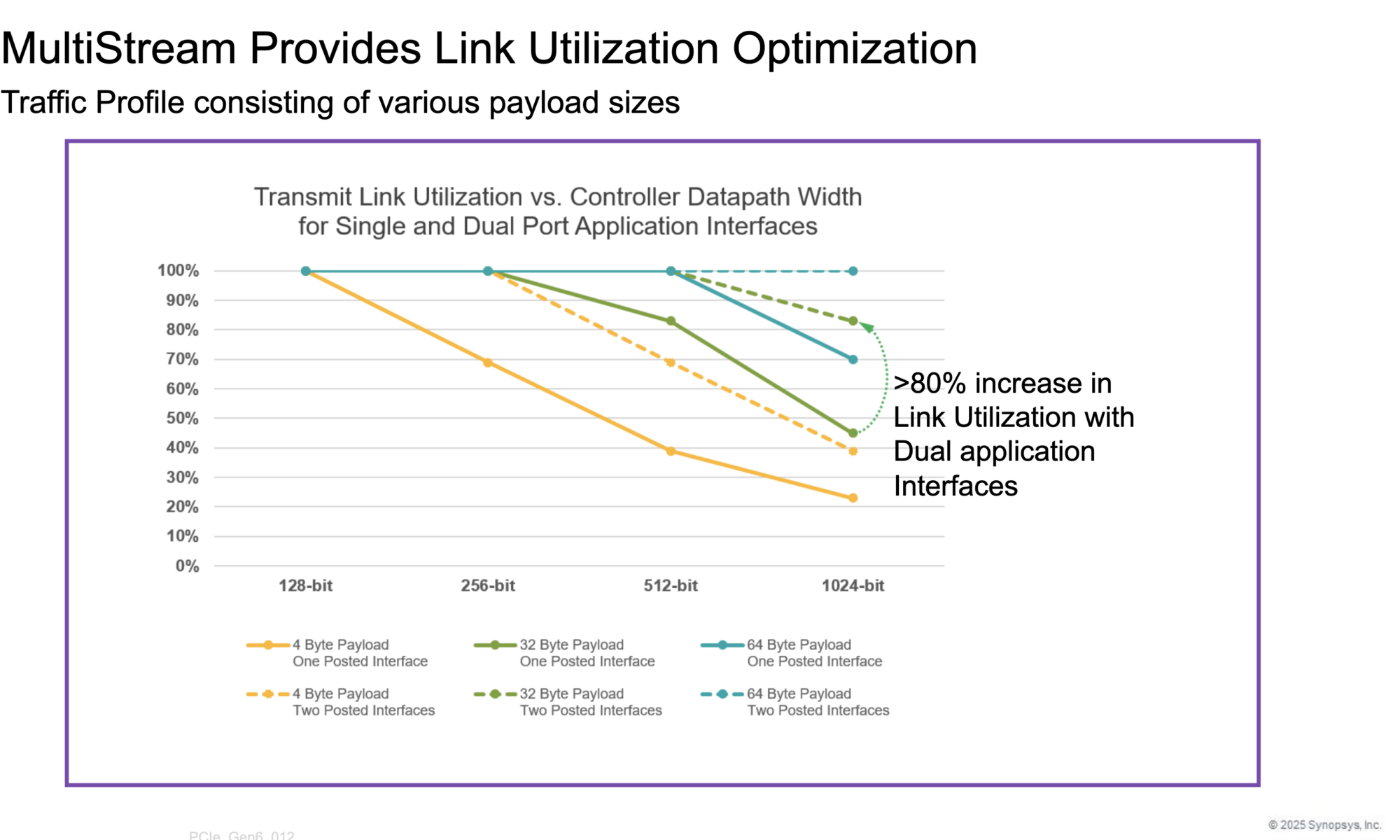
Multistream Architecture allows multiple TLPs to be accepted and serialized concurrently. Instead of one application interface per Flow Control (FC) type—Posted, Non-Posted, and Completions, Gen6 introduces two interfaces per FC type. This means the controller can ingest several independent packet streams at once while still maintaining strict ordering rules within an FC type.
This concurrency aligns naturally with FLIT mode. With multiple packets arriving per cycle, the controller can efficiently pack FLITs and maintain continuous transmission at 64 GT/s and 128 GT/s. In workloads dominated by small packets, Multistream Architecture improves link utilization by more than 80 percent. In short, the controller stays busy, and the link stays full.

From Gen5 to Gen6 and Forward to Gen7
The architectural leap from Gen5 to Gen6 is the most significant in PCIe’s history. Gen5 used NRZ signaling at 32 GT/s and relied on single-stream controllers. Gen6 doubles the rate, switches to PAM4, moves entirely to FLIT mode, widens datapaths, and introduces FEC. These changes demanded a controller that can handle far more work per cycle. Multistream Architecture was the response with a resilient design that allows Gen7 to use it without modification, simply doubling the signaling rate to 128 GT/s.
The same fundamental controller architecture scales across two generations of PCIe, streamlining SoC roadmaps and validation flows. This continuity matters a lot for designers.
Gen6 Application Interface Changes
In Gen5, only one TLP per cycle can be driven per FC type. If multiple traffic classes are active, an arbitration stage selects which one proceeds. Receive-side options (store-and-forward, cut-through, bypass) help latency but do not improve concurrency.
Gen6 redefines the model. Each FC type gains two transmit and two receive interfaces, letting applications push multiple TLPs concurrently. The controller attaches order numbers within each FC type to ensure correct sequencing, while allowing other FC types to progress independently. The receive side no longer requires bypass modes because parallel TLP arrival and serialization eliminate the bottleneck altogether. This higher-parallelism interface is essential for feeding a Gen6 or Gen7 controller at full rate.
Gen7 x16 Controller Considerations
A PCIe 7.0 x16 link delivers 2,048 Gb/s per direction—demanding a 1024-bit datapath operating at 2 GHz. Native application interfaces provide maximum bandwidth with minimal overhead. Many SoCs, however, depend on AXI, so Gen7 controllers integrate an AMBA bridge capable of sustaining full throughput without compromising latency. This ensures deployment flexibility across AI accelerators, CPUs, GPUs, and complex multi-die architectures.

Summary
Multistream Architecture is the critical enabler for PCIe operation at 64 GT/s and 128 GT/s. By allowing multiple TLPs to flow in parallel, it keeps FLIT pipelines full, maximizes link utilization, and accommodates the bursty, multichannel traffic typical of AI and HPC workloads. With more than 80 percent utilization gains for small-packet patterns and architectural continuity from Gen6 to Gen7, it forms the backbone of next-generation PCIe connectivity. Synopsys PCIe IP integrates this architecture with proven interoperability, ensuring that designers can fully exploit the performance of PCIe 6.0 and 7.0 in advanced AI systems.
You can watch the recorded webinar here.
Learn more about Synopsys PCIe IP Solutions here.
Also Read:
Synopsys + NVIDIA = The New Moore’s Law
WEBINAR: How PCIe Multistream Architecture is Enabling AI Connectivity
Lessons from the DeepChip Wars: What a Decade-old Debate Teaches Us About Tech Evolution
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.