

By Dr. Thang Minh Tran, CEO/CTO Simplex Micro
Today’s AI accelerators—whether built for massive data centers or low-power edge devices—face a common set of challenges: deep pipelines, complex data dependencies, and the high cost of speculative execution. These same concerns have long been familiar in high-frequency microprocessor design, where engineers must constantly balance performance with correctness. The deeper the pipeline, the greater the opportunity for instruction-level parallelism—but also the higher the risk of pipeline hazards, particularly read-after-write (RAW) dependencies.
Conventional scoreboard architectures, introduced in the 1970s and refined during the superscalar boom of the 1990s, provided only a partial fix. While functional, they struggled to scale with the growing complexity of modern pipelines. Each additional stage or execution lane increased the number of operand comparisons exponentially, introducing delays that made high clock rates harder to maintain.
The core function of a scoreboard—determining whether an instruction can safely issue—requires comparing destination operands of in-flight instructions with the source operands of instructions waiting to issue. In deep or wide pipelines, this logic quickly becomes a combinatorial challenge. The question I set out to solve was: could we accurately model operand timing without relying on complex associative lookups or speculative mechanisms?
At the time I developed the dual-row scoreboard, the goal was to support deterministic timing in wireless baseband chips, where real-time guarantees were essential and energy budgets tight. But over time, the architecture proved broadly applicable. Today’s workloads, particularly AI inference engines, often manage thousands of simultaneous operations. In these domains, traditional speculative methods—such as out-of-order execution—can introduce energy costs and verification complexity that are unacceptable in real-time or edge deployments.
My approach took a different path—one built on predictability and efficiency. I developed a dual-row scoreboard architecture that reimagines the traditional model with cycle-accurate timing and shift-register-based tracking, eliminating speculation while scaling to modern AI workloads. It split timing logic into two synchronized yet independent shift-register structures per architectural register, ensuring precise instruction scheduling without speculative overhead.
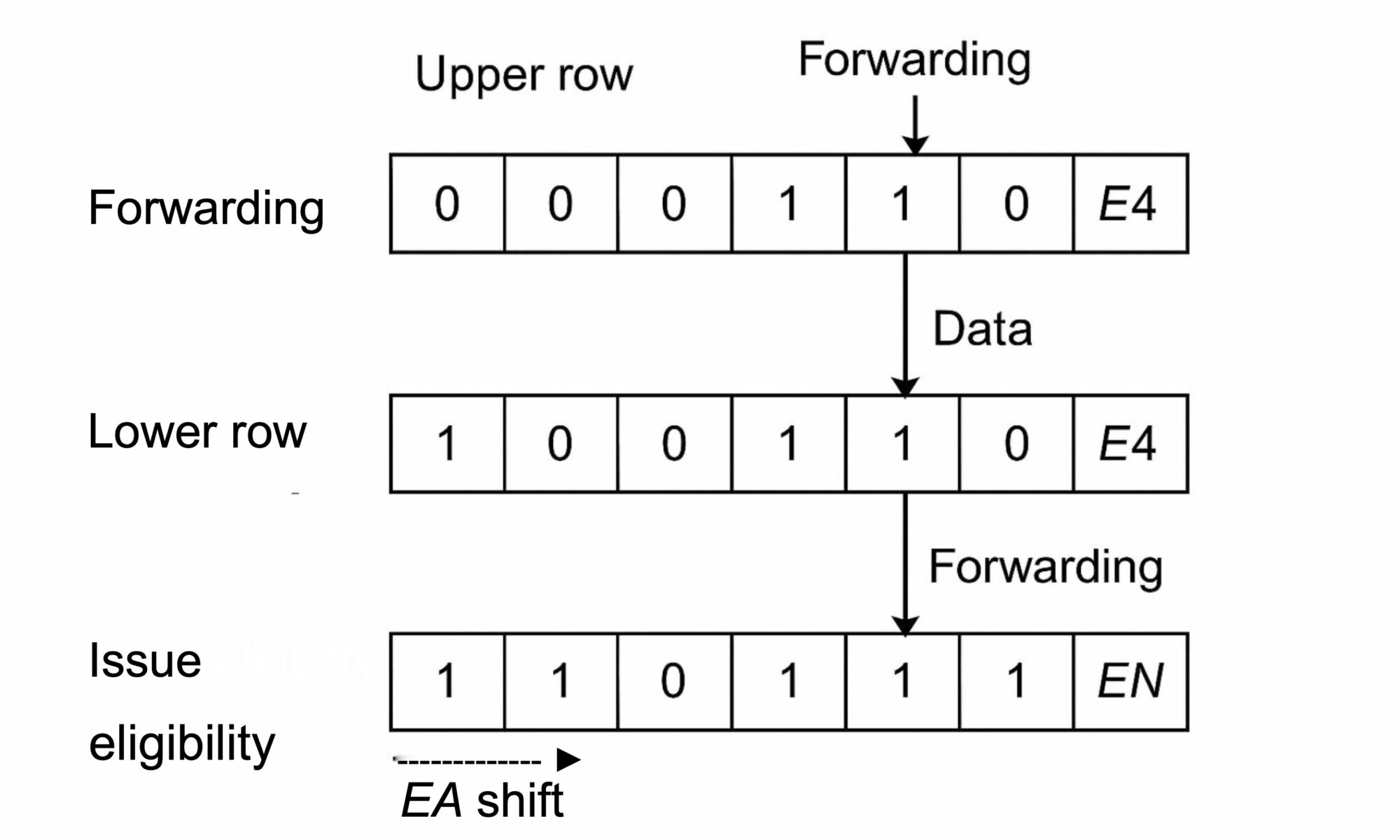
Scoreboard Mechanics – A Shift-Register Approach
Think of the dual-row scoreboard like a conveyor belt system. Each register has two tracks. The upper track monitors where the data is in the pipeline; the lower track monitors when it will be ready. Every clock cycle, the markers on these belts move one step—advancing the timeline of each instruction.
")
Forwarding Tracker – The Upper Row This row operates as a shift register that moves a singleton “1” across pipeline stages, precisely tracking the position of an instruction that will generate a result. This enables forwarding without directly accessing the register file.
Issue Eligibility Tracker – The Lower Row The second row independently tracks when a result will be available, using a string of “1”s starting from the earliest stage of availability. If a dependent instruction requires the data before it’s ready, issue is stalled. Otherwise, it proceeds immediately.
By comparing operand readiness with execution timing, the scoreboard makes a straightforward issue decision using the equation:
D = (EA – E) – EN + 1
Where:
- Eis the current stage of the producer instruction
- EAis the stage where the result first becomes available
- ENis the stage where the consumer will first need it
If D ≤ 0, the dependent instruction can issue safely. If D > 0, it must wait.
For example, suppose a result becomes available at EA = E3, the producer is currently at stage E2, and the consumer needs it at EN = E2. Then: D = (3 – 2) – 2 + 1 = 0 → the instruction can issue immediately. This simple arithmetic ensures deterministic execution timing, making the architecture scalable and efficient.
Integration and Implementation Each architectural register gets its own scoreboard “page,” which contains both the upper and lower rows. The scoreboard is thus a sparse, distributed structure—conceptually a 3D array indexed by register name (depth), pipeline stage (column), and logic type (upper vs. lower row). Because both rows shift synchronously with the pipeline clock, no multi-cycle arbitration or stall propagation is necessary.
The register file itself is simplified, because many operands never reach it. Data forwarding allows results to skip the register file entirely if they are consumed soon after being produced. This has both power and area benefits, particularly in small-process nodes where register file write ports are expensive.
Why This Still Matters Today
I built my architecture to solve a brutally specific problem: how to guarantee real-time execution in wireless modems where failure wasn’t an option. First rolled out in TI’s OMAP 1710, my design didn’t just power the main ARM+DSP combo—it shaped the dedicated modem pipeline supporting GSM, GPRS, and UMTS.
In the modem path, missing a deadline meant dropped packets—not just annoying like a lost video frame, but mission-critical. So I focused on predictable latency, tightly scoped memory, and structured task flow. That blueprint—born in the modem—now finds new life in AI and edge silicon, where power constraints demand the same kind of disciplined, deterministic execution.
For power-constrained environments like edge AI devices, speculative execution poses a unique challenge: wasted power cycles from mis predicted instructions can quickly drain energy budgets. AI inference workloads often handle thousands of parallel operations, and unnecessary speculation forces compute units to spend power executing instructions that will ultimately be discarded. The dual-row scoreboard’s deterministic scheduling eliminates this problem, ensuring only necessary instructions are issued at precisely the right time, maximizing energy efficiency without sacrificing performance.
The register file itself is simplified, because many operands never reach it. Data forwarding allows results to skip the register file entirely if they are consumed soon after being produced. In cases where the destination register is the same for both the producer and consumer instructions, the producer may not need to write back to the register file at all—saving even more power. This has both power and area benefits, particularly in small-process nodes where register file write ports are expensive.
This shift extends into the RISC-V ecosystem, where architects are exploring timing-transparent designs that avoid the baggage of speculative execution. Whether applied to AI inference, vector processors, or domain-specific accelerators, this approach provides robust hazard handling without sacrificing clarity, efficiency, or correctness.
Conclusion – A Shift in Architectural Thinking
For decades, microprocessor architects have balanced performance and correctness, navigating the challenges of deep pipelines and intricate instruction dependencies. Traditional out-of-order execution mechanisms rely on dynamic scheduling and reorder buffers to maximize performance by executing independent instructions as soon as possible, regardless of their original sequence. While effective at exploiting instruction-level parallelism, this approach introduces energy overhead, increased complexity, and verification challenges—especially in deep pipelines. The dual-row scoreboard, by contrast, provides precise, cycle-accurate timing without needing speculative reordering. Instead of reshuffling instructions unpredictably, it ensures availability before issuance, reducing control overhead while maintaining throughput.
In hindsight, the scoreboard isn’t just a control mechanism—it’s a new way to think about execution timing. Instead of predicting the future, it ensures the system meets it with precision—a principle that remains as relevant today as it did when it was first conceived. As modern computing moves toward more deterministic and power-efficient architectures, making time a first-class architectural concept is no longer just desirable—it’s essential.
Also Read:
Flynn Was Right: How a 2003 Warning Foretold Today’s Architectural Pivot
Voice as a Feature: A Silent Revolution in AI-Enabled SoCs
Feeding the Beast: The Real Cost of Speculative Execution in AI Data Centers
edictive Load Handling: Solving a Quiet Bottleneck in Modern DSPs
Share this post via:



Silicon Insurance: Why eFPGA is Cheaper Than a Respin — and Why It Matters in the Intel 18A Era