By Mark Tawfik
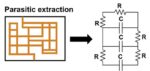
Parasitic extraction is essential in integrated circuit (IC) design, as it identifies unintended resistances, capacitances, and inductances that can impact circuit performance. These parasitic elements arise from the layout and interconnects of the circuit and can affect signal integrity, power consumption,… Read More
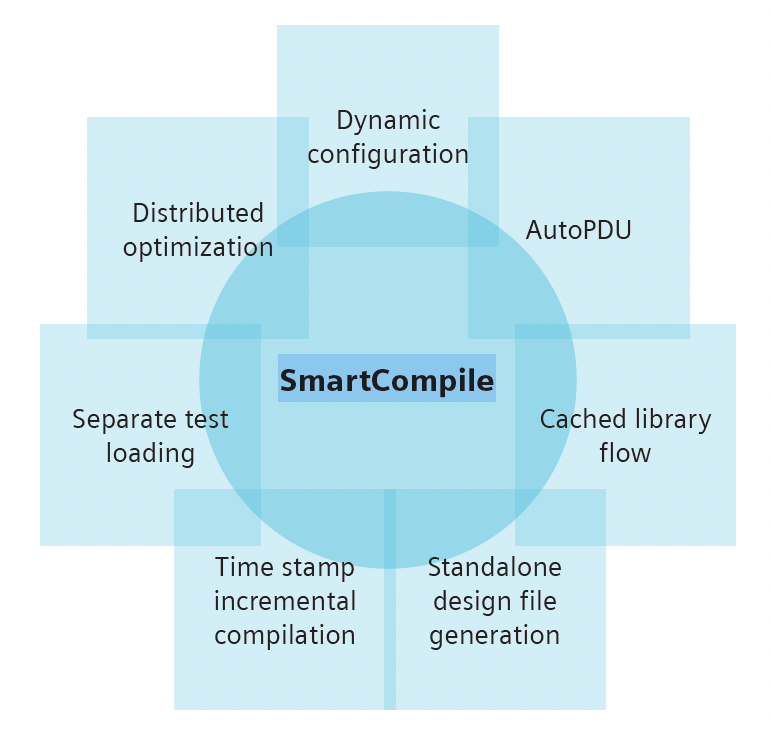
As the new name reflects, chip and system design were a major focus at DAC. So was the role of AI to enable those activities. But getting an AI-enabled design flow to work effectively across chip, subsystem and system-level design presents many significant challenges. One important one is effectively managing the vast amount of… Read More
As AI, HPC, and networking applications demand ever-higher compute and bandwidth, SoC complexity continues to grow. Traditional 50M ASIC equivalent gate FPGA prototyping systems have become less effective for full-chip verification at scale. Addressing this challenge, S2C introduced the Prodigy S8-100 Logic system, powered… Read More
Since the fall of the Roman Empire, France has played a defining role in shaping Western civilization. In the 9th century, Charlemagne—a Frank—united much of Europe under one rule, leaving behind a legacy so profound he is still remembered as the “Father of Europe.” While Italy ignited the Renaissance, it was 16th-century France… Read More
Dr. Maksym Plakhotnyuk, is the CEO and Founder of ATLANT 3D, a pioneering deep-tech company at the forefront of innovation, developing the world’s most advanced atomic-scale manufacturing platform. Maksym is the inventor of the first-ever atomic layer advanced manufacturing technology, enabling atomic-precision development… Read More
Carlos Pardo has a distinguished career as a manager in the microelectronics industry, excelling in leading R&D teams. He possesses extensive expertise in the high-tech silicon sector, encompassing both hardware and software development. Previously, he served as the Technical Director at SIDSA, where he managed R&D… Read More
Dan is joined by sureCore CEO Paul Wells. Paul has worked in the semiconductor industry for over 25 years including two years as director of engineering for Pace Networks, where he led a multidisciplinary, 70 strong product development team creating a broadcast quality video & data mini-headend. Before that, he worked for… Read More
With over 30 years of diverse industry experience, Darin leads SILICET, a semiconductor IP licensing firm. He spearheaded a strategic pivot to focus on a seamless LDMOS innovation that delivers unmatched cost, performance and reliability advantages – backed by a robust global patent portfolio. Prior to co-founding SILICET,… Read More
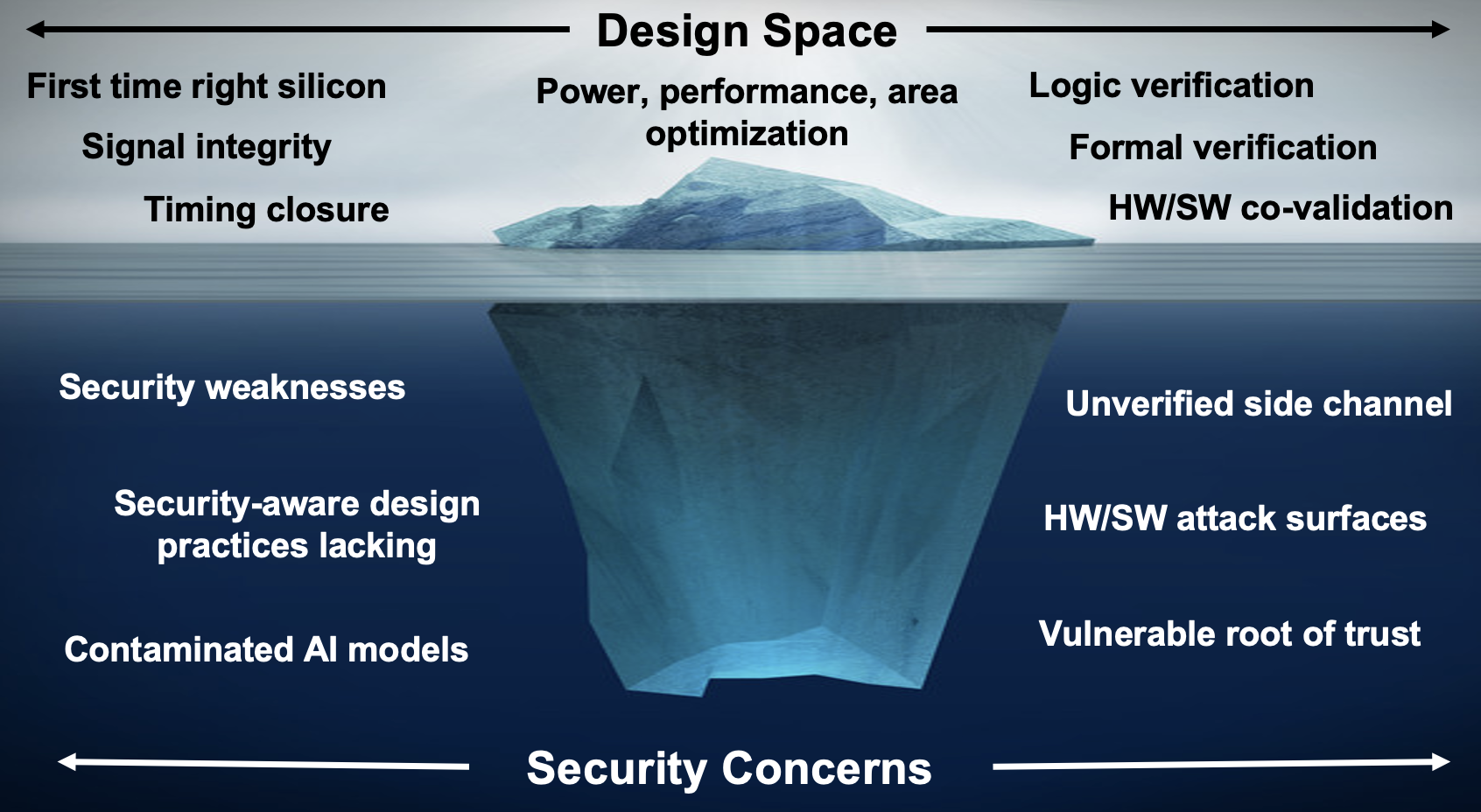
The semiconductor industry is rapidly moving beyond traditional 2D packaging, embracing technologies such as 3D integrated circuits (3D ICs) and 2.5D advanced packaging. These approaches combine heterogeneous chiplets, silicon interposers, and complex multi-layer routing to achieve higher performance and integration.… Read More
AI explosion is clearly driving semi-industry since 2020. AI processing, based on GPU, need to be as powerful as possible, but a system will reach optimum only if it can rely on top interconnects. The various sub-system need to be interconnected with ever more bandwidth and lower latency, creating the need for ever advanced protocol… Read More










Moore’s Law Wiki