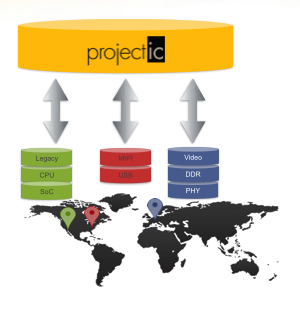
 Almost all large projects these days are distributed across multiple geographic locations. As the world rotates underneath the sun, the focus of activity moves too: Europe, US, China, India, back to Europe. For this to work effectively requires a collaborative platform designed for multi-site design efforts, a platform that communicates the current state of the design, planned changes, history, and delivers what each site requires with minimal user intervention and maximum efficiency.
Almost all large projects these days are distributed across multiple geographic locations. As the world rotates underneath the sun, the focus of activity moves too: Europe, US, China, India, back to Europe. For this to work effectively requires a collaborative platform designed for multi-site design efforts, a platform that communicates the current state of the design, planned changes, history, and delivers what each site requires with minimal user intervention and maximum efficiency.
There is a famous aphorism, attributed to Willem van der Pohl, that there are only three numbers in computer science: 0, 1 and infinity. When providing a service like IP data management, there are some things that you want to be centralized (only one of them) and otherwise you want an unrestricted number of them (sites, IPs, projects, bugs…). This gives you the best mixture of integrity and efficiency, giving the illusion of a single central repository without the obvious efficiency issues of actually keeping all the data at a single central site.
 Here are The Magnificent Seven of multi-site collaboration (or The Seven Samurai if you are more into Japanese cinema, Or 七人の侍 if you are really into Japanese cinema):
Here are The Magnificent Seven of multi-site collaboration (or The Seven Samurai if you are more into Japanese cinema, Or 七人の侍 if you are really into Japanese cinema):
[LIST=1]
Centrally Defined Configuration Management: ProjectIC has the PiServer central database of IP and project metadata including the hierarchical resource tree for each project collected from user workspaces.
IP-centric Bug Tracking: Off-the-shelf bug-tracking tools such as Jira and Bugzilla don’t work well in an IP context since each IP is usually considered a separate “project” in the bug-tracking database. With hundreds of IPs in a typical SoC and perhaps thousands in a large semiconductor company this is impractical to use directly. ProjectIC will query the bug database for bugs associated with each IP version and present a consolidated hierarchical view of bugs found for the whole SoC.
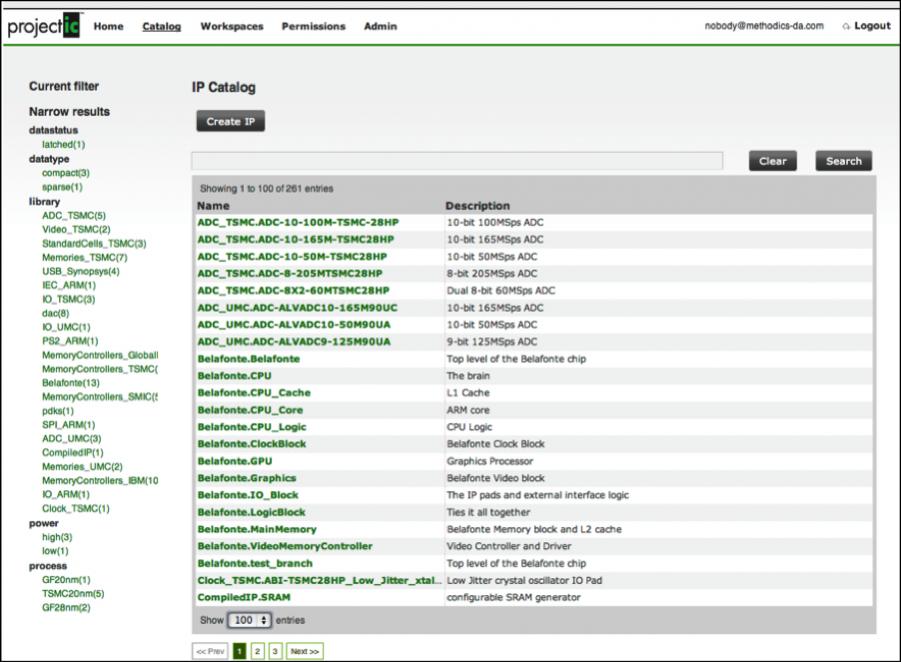
Centralized IP Catalog: there needs to be a centrally defined database to discover the existing IP in the company, including its quality, the location of the files in the data management system, all the available versions of the IP, which versions are recommended for use by the IP owner, which projects are using these versions and so on. The ProjectIC PiWeb catalog has an easy to query searchable database with multiple levels of metadata for organizing IPs including labels, custom properties, project based etc. This catalog is auto-updating and self-regulating so that when IPs and IP versions are introduced to the system from with within a project they are automatically added to the catalog (this is important: if manual update is required then it can be guaranteed that the data is stale if not plain wrong).
Multi-Site Data Replication: Although the IP metadata needs to be centralized, the data management repositories themselves need to be replicated to reduce the time to deliver files to user workspaces. For example, one underlying data management environment is Perforce (with its Edge and Replica servers) where metadata queries, commits and syncs can happen locally without the need for WAN access, all without any user interaction.
Decentralized Data Management: Another method for reducing multi-site data latencies is to maintain the master Subversion or Perforce repository at the remote site if that is where the majority of the development activity is taking place. ProjectIC allows the repository location to be defined on a pre-IP basis so that workspace creation will query the local server and reduce WAN delays
Multi-site IP caches: An important part of the Methodics multi-site solution is the use of IP Caches to maintain local read-only versions of popular IPs for consumption at remote sites. These are updated and propagated automatically as part of the IP release process and mean that users who only need read access to a particular IP can set that IP to “refer” in their workspace configuration and ProjectIC will manage the reference automatically.
Large Dataset Block-level Replication: A slightly different technique for reducing multi-site delays is to use Warpstor to maintain master versions of the important project workspaces and deliver changes multi-site between these masters incrementally at the file-system block level, as new releases are made. This reduces the need for large DM checkouts into a workspace since the user workspaces can use lightweight clones using these replicated masters.
See also WarpStor, the Data Tardis: Small on the Outside, Large on the Inside
The white paper Methodics—Architected for Multi-Site Collaboration is here.
Share this post via:






Comments
0 Replies to “The Magnificent Seven of International IP Management”
You must register or log in to view/post comments.