
In 2003, legendary computer architect Michael J. Flynn issued a warning that most of the industry wasn’t ready to hear. The relentless march toward more complex CPUs—with speculative execution, deep pipelines, and bloated instruction handling—was becoming unsustainable. In a paper titled “Computer Architecture and Technology: Some Thoughts on the Road Ahead,” Flynn predicted that the future of computing would depend not on increasingly intricate general-purpose processors, but on simple, parallel, deterministic, and domain-specific designs.
Two decades later, with the cracks in speculative execution now exposed and the rise of AI accelerators reshaping the hardware landscape, Flynn’s critique looks prophetic. His call for architectural simplicity, determinism, and specialization is now echoed in the design philosophy of industry leaders like Google, NVIDIA, Meta, and emerging players like Simplex Micro. Notably, Dr. Thang Tran’s recent patents—Microprocessor with Time-Scheduled Execution for Vector Instructions and Microprocessor with a Time Counter for Statically Scheduled Execution—introduce a deterministic vector processor design that replaces out-of-order speculation with time-based instruction scheduling.
This enables predictable high-throughput execution, reduced power consumption, and simplified hardware verification. These innovations align directly with Flynn’s assertion that future performance gains would come not from complexity, but from disciplined simplicity and explicit parallelism.
The Spectre of Speculation
Flynn’s critique of speculative execution came well before the industry was rocked by the Spectre and Meltdown vulnerabilities in 2018. These side-channel attacks exploited speculative execution paths in modern CPUs to leak sensitive data across isolation boundaries—an unintended consequence of the very complexity Flynn had warned against. The performance gains of speculation came at a steep cost: not just in power and verification effort, but in security and trust.
In hindsight, Flynn’s warnings were remarkably prescient. Long before Spectre and Meltdown exposed the dangers of speculative execution, Flynn argued that speculation was a fragile optimization: it introduced deep design disruption, made formal verification more difficult, and consumed power disproportionately to its performance gains. The complexity it required—branch predictors, reorder buffers, speculative caches—delivered diminishing returns as workloads became increasingly parallel and memory-bound.
Today, a quiet course correction is underway. Major chipmakers like Intel are rethinking their architectural priorities. Intel’s Lunar Lake and Sierra Forest cores prioritize efficiency over aggressive speculation, optimizing for throughput per watt. Apple’s M-series chips use wide, out-of-order pipelines, but they increasingly emphasize predictable latency and compiler-led optimization over sheer speculative depth. In the embedded space, Arm’s Cortex-M and Neoverse lines have trended toward simplified pipelines and explicit scheduling, often foregoing speculative logic entirely to meet real-time and power constraints.
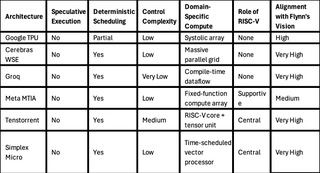
Perhaps most significantly, the open RISC-V ecosystem is enabling a new generation of CPU and accelerator designers to build from first principles—often without speculative baggage. Vendors like Simplex Micro are championing deterministic, low-overhead execution models, leveraging vector and matrix extensions or predictive scheduling in place of speculation. These choices directly reflect Flynn’s thesis: when correctness, power, and scalability matter more than peak IPC, simplicity wins.
It’s worth noting that Tenstorrent, while often associated with RISC-V innovation, does not currently implement deterministic scheduling in its vector processor. Their architecture incorporates speculative and out-of-order execution to optimize throughput, resulting in higher control complexity. While this boosts raw performance, it diverges from Flynn’s call for simplicity and predictability. Nonetheless, Tenstorrent’s use of domain-specific acceleration and parallelism aligns with other aspects of Flynn’s vision.

A Parallel Future: AI Chips and Flynn’s Vision
Nowhere is Flynn’s vision more alive than in the rise of AI accelerators. From Google’s Tensor Processing Units (TPUs) to NVIDIA’s Tensor Cores, from Cerebras’ wafer-scale engines to Groq’s dataflow processors, the trend is clear: ditch speculative complexity, and instead embrace massively parallel, deterministic computing.
Google’s TPU exemplifies this shift. It forgoes speculative execution, out-of-order logic, and deep control pipelines. Instead, it processes matrix operations through a systolic array—a highly regular, repeatable architecture ideal for AI workloads. This approach delivers high throughput with deterministic latency, matching Flynn’s call for simple and domain-optimized hardware.
Cerebras Systems takes this concept even further. Its Wafer Scale Engine integrates hundreds of thousands of processing elements onto a single wafer-sized chip. There’s no cache hierarchy, no branch prediction, no speculative control flow—just massive, uniform parallelism across a tightly connected grid. By optimizing for data locality and predictability, Cerebras aligns directly with Flynn’s argument that regularity and determinism are the keys to scalable performance.
Groq, co-founded by TPU architect Jonathan Ross, builds chips around compile-time scheduled dataflow. Their architecture is radically deterministic: there are no instruction caches or branch predictors. All execution paths are defined in advance, eliminating the timing variability and design complexity of speculative logic. The result is a predictable, software-driven execution model that reflects Flynn’s emphasis on explicit control and simplified verification.
Even Meta (formerly Facebook), which once relied entirely on off-the-shelf GPUs, has embraced Flynn-style thinking in its custom MTIA (Meta Training and Inference Accelerator) chips. These processors are designed for inference workloads like recommendation systems, emphasizing predictable throughput and energy efficiency over raw flexibility. Meta’s decision to design in-house hardware tailored to specific models echoes Flynn’s assertion that different computing domains should not be forced into one-size-fits-all architectures.
Domain-Specific Simplicity: The DSA Revolution
Flynn also predicted the fragmentation of computing into domain-specific architectures (DSAs). Rather than a single general-purpose CPU handling all workloads, he foresaw that servers, clients, embedded systems, and AI processors would evolve into distinct, streamlined architectures tailored for their respective tasks.
That prediction has become foundational to modern silicon design. Today’s hardware ecosystem is rich with DSAs:
- AI-specific processors (TPUs, MTIA, Cerebras)
- Networking and storage accelerators (SmartNICs, DPUs)
- Safety-focused microcontrollers (e.g., lockstep RISC-V cores in automotive)
- Ultra-low-power edge SoCs (e.g., GreenWaves GAP9, Kneron, Ambiq)
These architectures strip out unnecessary features, minimize control complexity, and focus on maximizing performance-per-watt in a given domain—exactly the design goal Flynn outlined.
Even GPUs have evolved in this direction. Originally designed for graphics rendering, GPUs now incorporate tensor cores, sparse compute units, and low-precision pipelines, effectively becoming DSAs optimized for machine learning rather than general-purpose parallelism.
The Legacy of Simplicity
Flynn’s 2003 message was clear: Complexity is not scalable. Simplicity is. Today’s leading architectures—from TPUs to RISC-V vector processors—have adopted that philosophy, often without explicitly crediting the foundation he laid. The resurgence of dataflow architectures, explicit scheduling, and deterministic pipelines shows that the industry is finally listening.
And in an era where security, power efficiency, and real-time reliability matter more than ever—especially in AI inference, automotive safety, and edge computing—Flynn’s vision of post-speculation computing is not just relevant, but essential.
He was right.
References
- Flynn, M.J. (2003). Computer Architecture and Technology: Some Thoughts on the Road Ahead. Keynote at Computing Frontiers Conference.
- Spectre and Meltdown
- Google TPU: Jouppi, N. et al., ‘In-Datacenter Performance Analysis of a Tensor Processing Unit,’ ISCA 2017.
- Cerebras WSE
- Groq: “A Software-defined Tensor Streaming Multiprocessor…”
- META MTIA V2 Chip:
- Tenstorrent Overview: Products and Software
- WO2024118838A1: Latency-tolerant scheduling and memory-efficient RISC-V vector processor. https://patents.google.com/patent/WO2024118838A1/en
- WO2024015445A1: Predictive scheduling method for high-throughput vector processing. https://patents.google.com/patent/WO2024015445A1/en
Also Read:
Andes Technology: Powering the Full Spectrum – from Embedded Control to AI and Beyond
From All-in-One IP to Cervell™: How Semidynamics Reimagined AI Compute with RISC-V
Andes Technology: A RISC-V Powerhouse Driving Innovation in CPU IP
Share this post via:



Comments
5 Replies to “Flynn Was Right: How a 2003 Warning Foretold Today’s Architectural Pivot”
You must register or log in to view/post comments.