
The rapid proliferation of LLMs and other AI applications, and of high-end GPU platforms that run them, is putting intense pressure on the performance requirements for memory technologies. Designers need to be keenly aware of how to make the most of their memory and controller choices, which can be moving targets given the rapid pace of new developments. To wit, Rambus is launching its cutting-edge HBM4E memory controller IP product with AI training applications in mind. With this launch, a webinar hosted by Nadish Kamath, Director of Product Marketing at Rambus, explores HBM technology and makes the case for selecting HBM4E for the most advanced AI training applications.
The “memory wall” versus AI training
Kamath starts with a reference to the “memory wall,” which is an ongoing challenge for computing system designers. Traditional dynamic RAM technology has steadily advanced – and when viewed on its own timeline, the progress looks good – but Kamath says it’s not anywhere near keeping pace with processor technology. Over the past two decades, processor technology has improved 60,000x. Over the same period, DRAM bandwidth has increased by only 100x, and interconnect bandwidth by even less, 30x.

A major reason for this disparity is the difficulty of achieving the broad interoperability needed to recapture the massive investments in DRAM fabrication capacity if memory interface specifications advance too quickly. Mainstream memory must be usable across as many processor architectures as possible. Ditto for interconnect specifications; in fact, that situation may be even more economically acute. Processors, however, have fewer constraints. GPU internal architecture, especially given multicore technology, has grown by leaps and bounds while maintaining consistent interfaces to other off-chip subsystems.
However, as is often the case, there’s a catch. Massive GPUs targeting AI training are so fast now that it’s getting difficult to keep their engines fed with data from the memory subsystem. Because AI training data is, by its very nature, a unique stream that changes from sample to sample, caching, which has been a boon to CPU technology, is much less effective. That means the performance burden now falls on main memory, and advanced memory architectures must prioritize raw bandwidth on optimized interfaces.
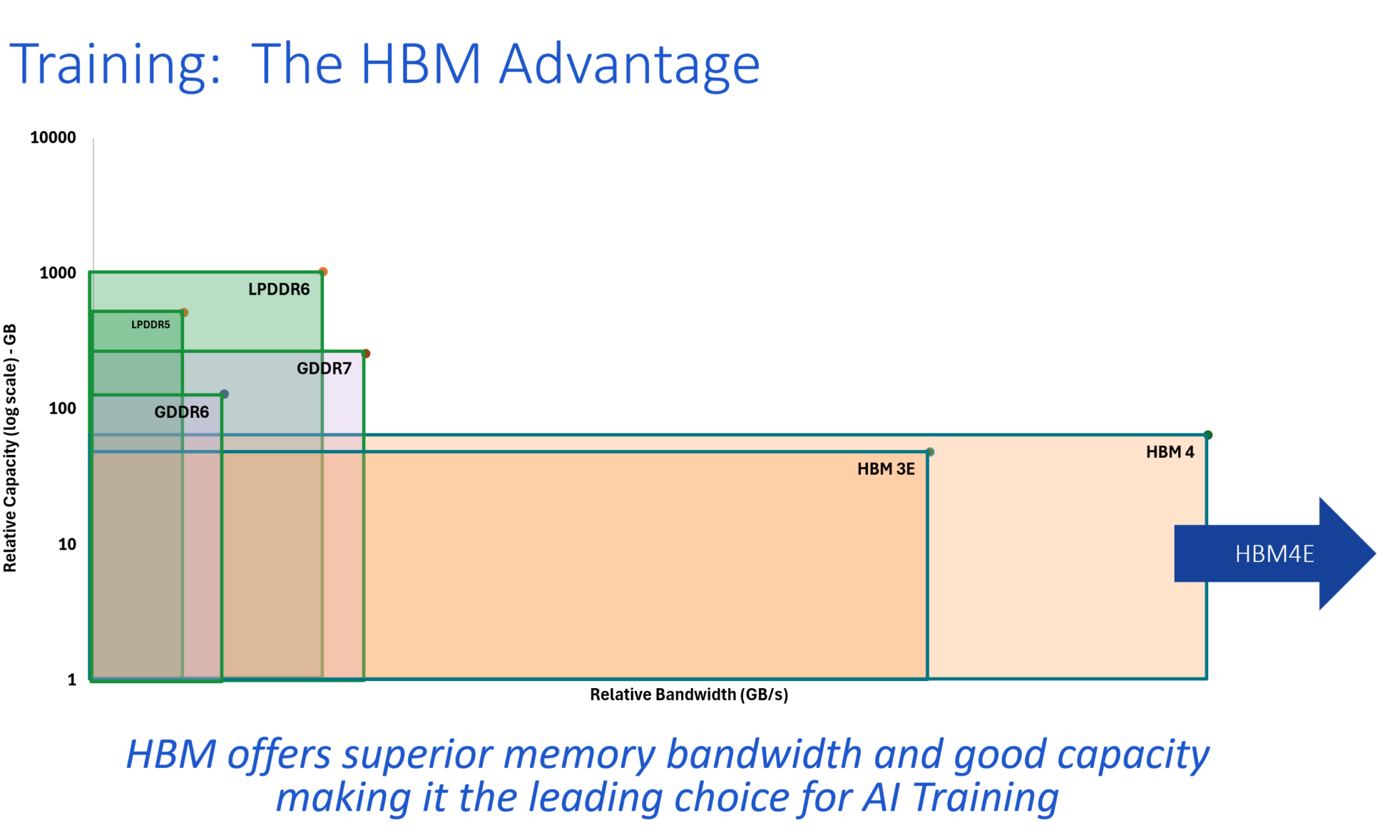
Advantages of HBM in AI training
That’s where HBM comes in. Where other technologies like LPDDR6 accompany consumer-level GPUs, offering a balance of performance, capacity, and cost, HBM sits squarely in the higher-performance space for GPUs targeting AI training servers. The HBM specifications continue to stretch in several dimensions – wider buses, faster transfer rates, higher stack heights with multiple HBM dies in a 3D footprint, and larger individual die capacity. HBM4E uses the same 2048-bit interface as HBM4 and increases the transfer rate by up to 2x.

Rambus is focusing on HBM memory controller IP, and carving out an advantage there. Kamath says lessons learned from 100+ HBM design wins and decades of memory interface expertise have rolled into their new HBM4E controller IP offering. Where competitive HBM controller IP products may be limited in the transfer speeds they can achieve, Rambus is leveraging its experience to deliver the full 16 Gb/sec per pin from its updated HBM4E controller, translating to 4.1 TB/s of bandwidth per HBM4E memory device.
There’s more in the webinar, as Kamath steps through additional information on AI use cases, background on the HBM architecture, and a full description of their HBM4E controller’s capabilities. If you’re trying to get more out of AI training servers and racks, give this a watch.
Register for the webinar today: HBM4E Advances Bandwidth Performance for AI Training
Also Read:
How Memory Technology Is Powering the Next Era of Compute
Siemens Wins Best in Show Award at Chiplet Summit and Targets Broad 3D IC Design Enablement
Siemens Fuse EDA AI Agent Releases to Orchestrate Agentic Semiconductor and PCB Design
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.