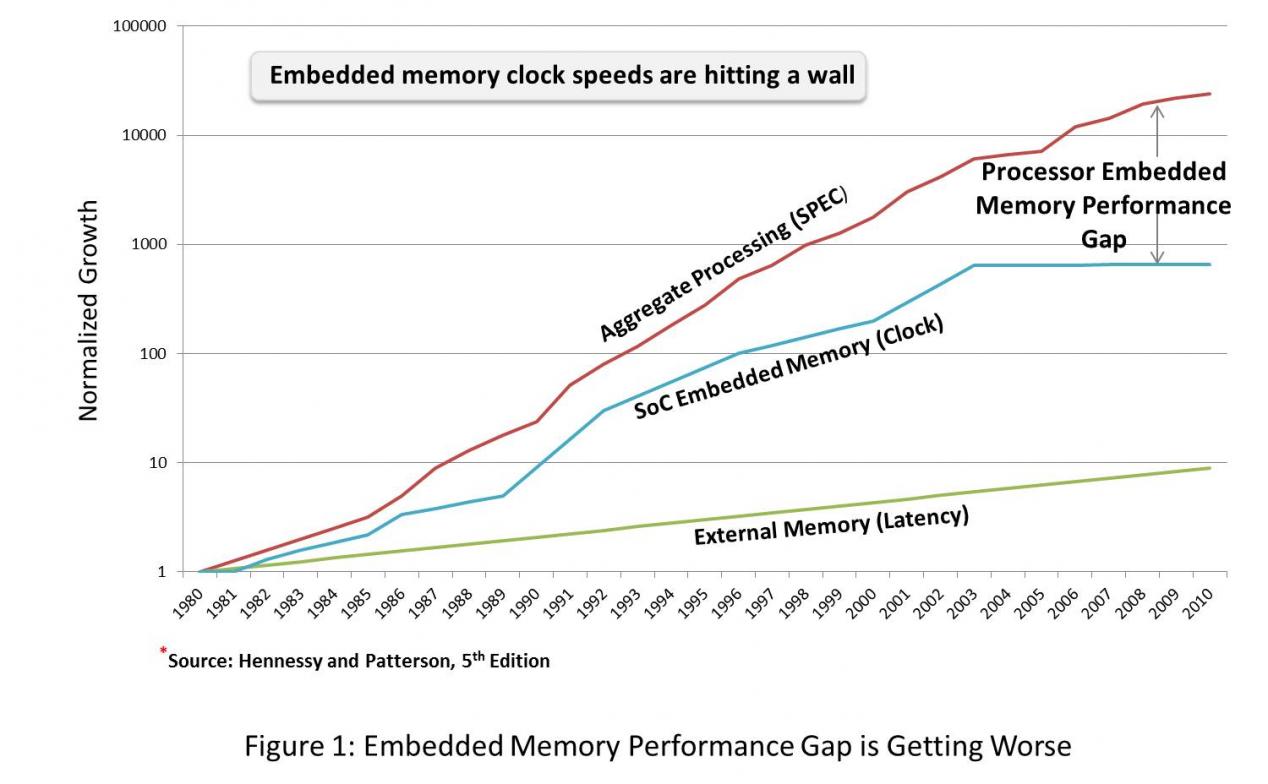


 Remember the processor-memory gap— a situation where the processor is forced to stall while waiting for a memory operation to complete? This was largely a result of the high latency required for off chip memory accesses. Haven’t we solved that problem now with SoCs? SoCs are typically architected with their processors primarily accessing embedded memory, and accessing external memory only when absolutely necessary. However, while on-chip memory access latency is still a concern, embedded memories are also required to respond to back‐to‐back sustained access requests issued by a processor or processors. In fact, networking data pipelines and multicore processors can hammer memory with a multitude of simultaneous memory accesses to unique random addresses, and the total number of aggregated memory accesses has been dramatically increasing. So once again, system architects are up against a processor-memory gap, this time with embedded memory. And as a result, embedded memory performance has become the limiting factor in many applications (figure 1).
Remember the processor-memory gap— a situation where the processor is forced to stall while waiting for a memory operation to complete? This was largely a result of the high latency required for off chip memory accesses. Haven’t we solved that problem now with SoCs? SoCs are typically architected with their processors primarily accessing embedded memory, and accessing external memory only when absolutely necessary. However, while on-chip memory access latency is still a concern, embedded memories are also required to respond to back‐to‐back sustained access requests issued by a processor or processors. In fact, networking data pipelines and multicore processors can hammer memory with a multitude of simultaneous memory accesses to unique random addresses, and the total number of aggregated memory accesses has been dramatically increasing. So once again, system architects are up against a processor-memory gap, this time with embedded memory. And as a result, embedded memory performance has become the limiting factor in many applications (figure 1).
At Memoir Systems, we believe that the performance limitations of embedded memories are largely a result of the way that the problem has been conceptualized. In fact, we have found it is possible to improve memory performance by a factor of ten using currently available technology and standard processes. In the past, thinking about embedded memories was limited to a purely circuit- and process-oriented approach. Thus, the focus was on maximizing the number of transistors on a chip and cranking up the clock speed. This was successful up to a point, but as transistors approach atomic dimension, as an industry, we ran into fundamental physical barriers.
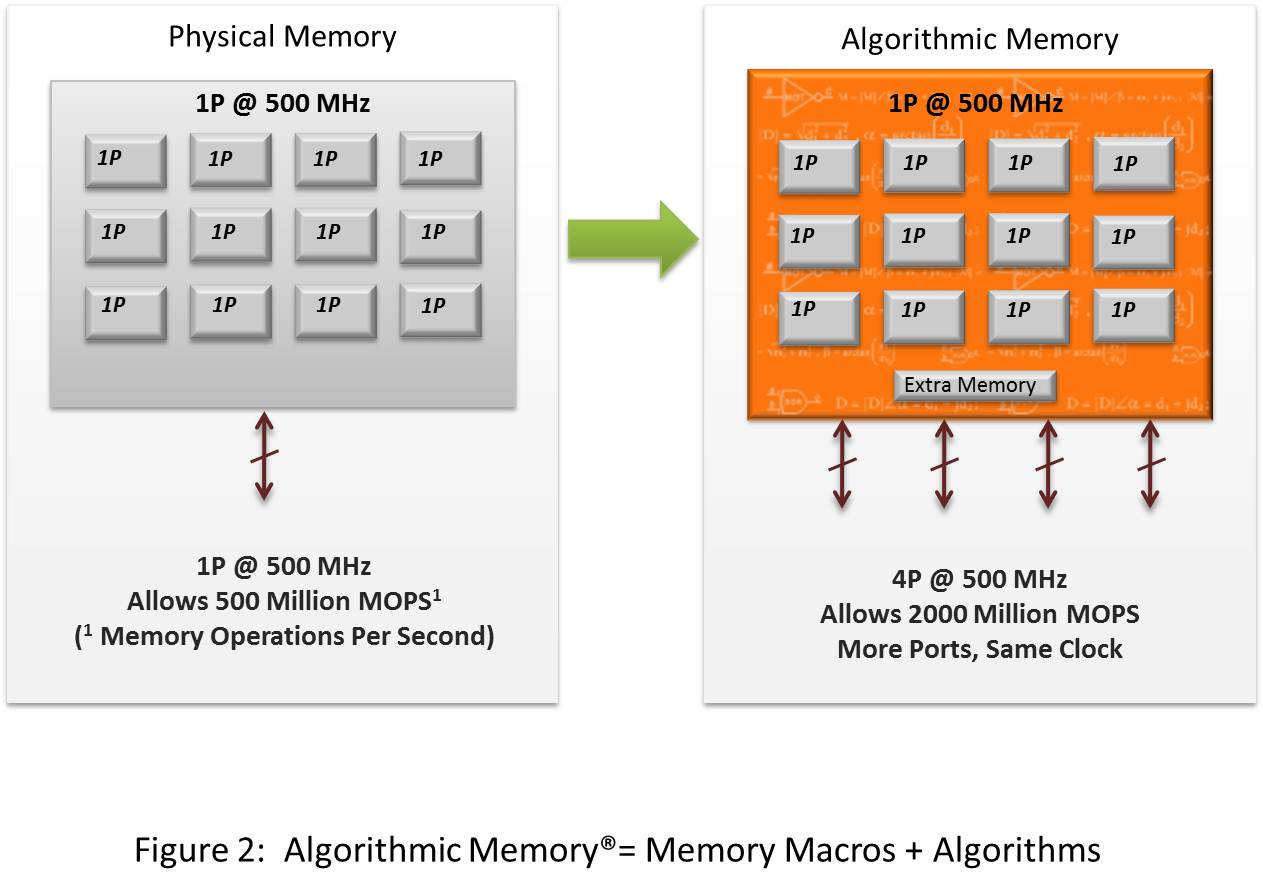
At Memoir we have taken an entirely new approach with ourAlgorithmic Memory technology. Algorithmic Memories operate by adding logic to existing embedded memory macros. Within the memories, algorithms intelligently read, write, and manage data in parallel using a variety of techniques such as buffering, virtualization, pipelining, and data encoding. These techniques are woven together to create a new memory that internally processes memory operations an order of magnitude faster and with guaranteed performance. This increased performance capability is made available to the system through additional memory ports such that many more memory access requests can be processed in parallel within a single clock cycle as shown in figure 2. The concept of using multi-port memories as a means of multiplying memory performance mirrors the trend of using multicore processors to increase performance over uniprocessors. In both cases, it is the parallel architecture rather than faster clock speeds that drive performance gains.
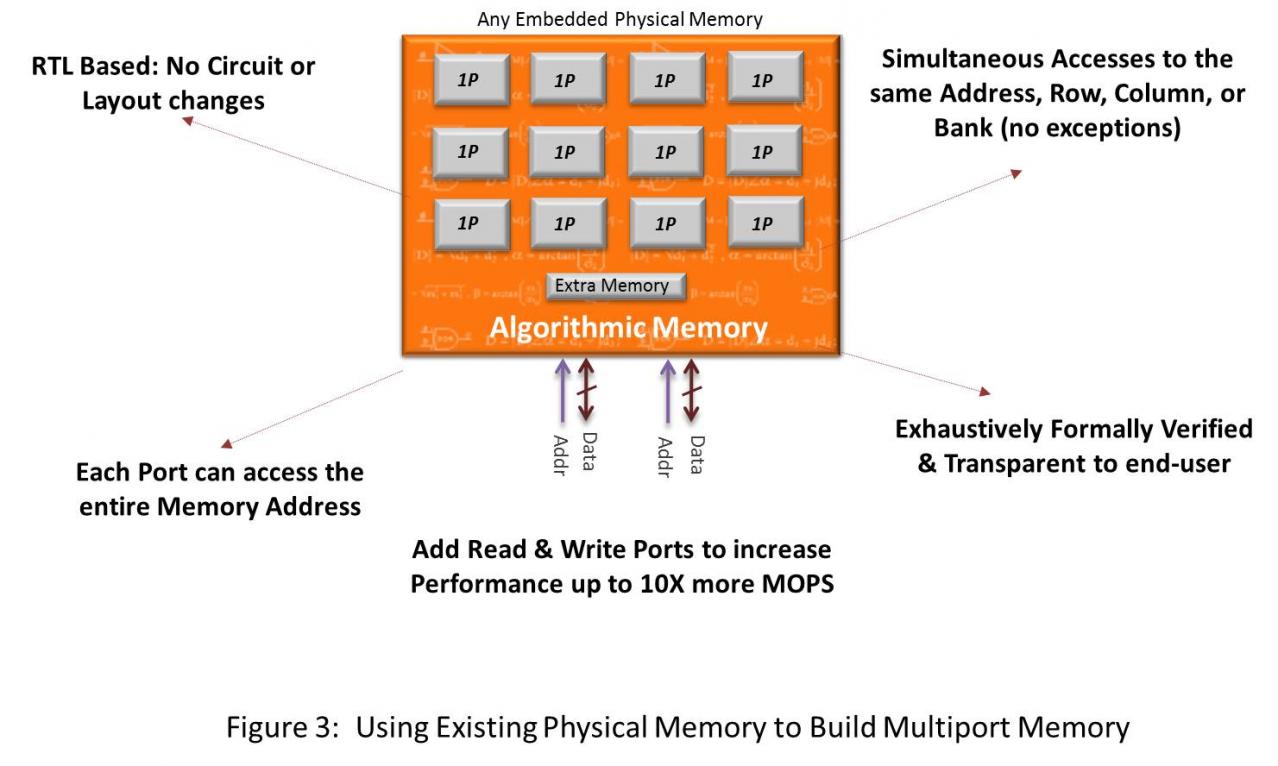
 Algorithmic Memory technology is implemented as a soft RTL. The resulting solutions appear exactly as standard multi-port embedded memories. The new memories employ dozens of techniques to accelerate performance or reduce area and power requirements. However, perhaps the greatest benefits of Algorithmic Memory come not from the individual algorithms, but rather in how they are integrated into an elegant system (figure 3). In this system, the memories not only perform better, but their performance is fully deterministic. Furthermore, not only can new memories be created very rapidly, but they are also automatically exhaustively formally verified and, since they are built on existing embedded memories, no additional silicon validation is required.
Algorithmic Memory technology is implemented as a soft RTL. The resulting solutions appear exactly as standard multi-port embedded memories. The new memories employ dozens of techniques to accelerate performance or reduce area and power requirements. However, perhaps the greatest benefits of Algorithmic Memory come not from the individual algorithms, but rather in how they are integrated into an elegant system (figure 3). In this system, the memories not only perform better, but their performance is fully deterministic. Furthermore, not only can new memories be created very rapidly, but they are also automatically exhaustively formally verified and, since they are built on existing embedded memories, no additional silicon validation is required.
 Algorithmic Memory gives memory architects a powerful tool to rapidly and reliably create the exact memories they need for a given application. Most importantly, though, it empowers system architects with new techniques to overcome the processor-memory gap, and further unlock SoC performance.
Algorithmic Memory gives memory architects a powerful tool to rapidly and reliably create the exact memories they need for a given application. Most importantly, though, it empowers system architects with new techniques to overcome the processor-memory gap, and further unlock SoC performance.
Dr. Sundar Iyer
Co-Founder & CTO





Silicon Insurance: Why eFPGA is Cheaper Than a Respin — and Why It Matters in the Intel 18A Era