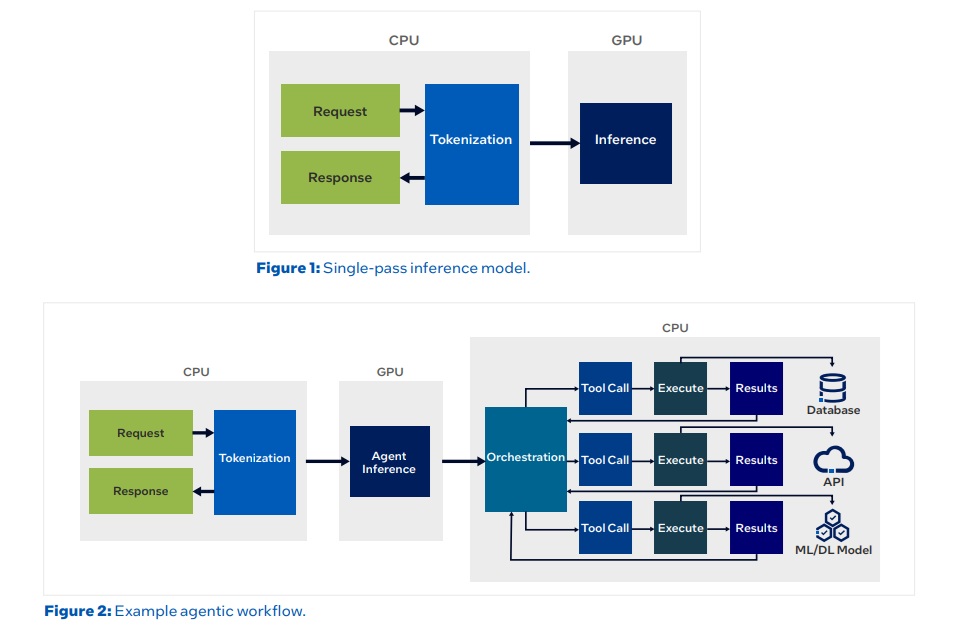

Agentic AI workloads are reshaping the compute requirements of modern data center infrastructure by shifting performance bottlenecks from GPU-centric inference to CPU-heavy orchestration and workflow management. Traditional AI inference pipelines relied primarily on GPUs performing a single forward pass, where input tokenization, model execution, and output generation occurred sequentially. However, emerging agentic AI systems transform inference into a distributed, multi-step process involving planning, tool invocation, validation, and iterative reasoning. This architectural change introduces substantial CPU demand, making CPU capacity a critical factor in maintaining system throughput and overall cost efficiency.

In agentic workflows, CPUs perform orchestration tasks such as control flow management, branching logic, retries, and coordination between multiple agents and external services. Each agent invocation may require interaction with databases, APIs, search engines, or vector stores, all of which generate additional CPU, memory, and I/O overhead. Moreover, reasoning-heavy workloads often require sandboxed execution environments for validation and testing. These iterative loops create multi-turn workflows in which CPUs determine end-to-end throughput. When CPU resources are insufficient, GPUs remain idle while waiting for preprocessing, tool execution, or verification steps to complete, resulting in inefficient use of expensive accelerator hardware.
Experimental benchmarks reinforce the significance of CPU workloads in agentic pipelines. In a financial anomaly detection workflow modeled after regulatory filing analysis, CPUs handled tasks such as data loading, baseline calculation, anomaly detection, document retrieval, and enrichment through web searches. The results demonstrated that CPU operations dominated the total runtime, with enrichment alone consuming significantly more time than the GPU-based model inference step. This highlights that inference acceleration alone cannot optimize performance; instead, system balance between CPU orchestration and GPU computation is required.
A second benchmark focusing on AI-assisted code generation further illustrated CPU bottlenecks. In this workflow, the GPU generated candidate solutions, while CPUs executed and verified code within sandboxed environments. Across more than two thousand tasks, CPU-based sandbox execution consumed slightly more time than GPU code generation, despite utilizing a high-core-count system. The CPU phase involved subprocess management, test execution, and result analysis, demonstrating that validation loops can rival or exceed inference time in agentic systems. These findings indicate that increasing GPU performance alone does not improve overall throughput without proportional CPU scaling.
Infrastructure sizing recommendations emerging from these experiments emphasize maintaining balanced CPU-to-GPU ratios. Current guidance suggests a ratio between 1:1 and 1.4:1 CPUs to GPUs, equivalent to approximately 86 to 120 CPU cores per GPU, depending on workload characteristics. Smaller models generating tokens more quickly require additional CPU capacity to keep GPUs saturated, while more powerful CPUs can reduce the required ratio. Future high-performance GPUs may further increase CPU demand, potentially pushing ratios higher when orchestration complexity grows.
The implications extend beyond performance optimization. Under-provisioned CPU resources can introduce latency in orchestration, delay tool execution, and slow verification loops, all of which reduce GPU utilization and increase operational costs. Conversely, scaling CPUs ensures continuous data preparation, coordination, and validation, allowing GPUs to operate at maximum efficiency. This system-level balance mirrors microservices architectures, where overall performance depends on the slowest component rather than the fastest.
Bottom line: As agentic AI continues to evolve, CPUs will play an increasingly central role in inference infrastructure. The transition from single-pass inference to multi-step workflows shifts value toward orchestration, coordination, and runtime management. Organizations deploying agentic systems must therefore reconsider traditional GPU-centric scaling strategies and instead design balanced architectures that provision sufficient CPU capacity. By aligning CPU and GPU resources, data centers can sustain throughput, minimize idle accelerators, and optimize total cost of ownership for next-generation AI deployments.
Also Read:
Silicon Insurance: Why eFPGA is Cheaper Than a Respin — and Why It Matters in the Intel 18A Era
Captain America: Can Elon Musk Save America’s Chip Manufacturing Industry?
Intel to Compete with Broadcom and Marvell in the Lucrative ASIC Business
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.