Per DK:
"Intel’s 22FFL metal stack is similar to a foundry SoC process and includes three novel layers. The metal layer pitches are all integer multiples and generally optimized for low-cost. Intel’s team chose a minimum pitch of 90nm for the lowest 6 layers. Unlike previous Intel process technologies, this metal 1X layer supports complex routing using only single-patterning lithography, eliminating a second exposure compared to the 22nm SoC process. Two thick metal upper layers are available for routing power and ground, and they are also used to form inductors and metal-insulator-metal capacitors. The 1080nm pitch metal layer is re-used from existing process flows, but the 4000nm pitch top metal layer is entirely new. In addition, the process flow supports optional 2X, 4X, and 8X pitch metal layers; the 720nm 8X pitch is also a new layer defined specifically for the 22FFL node.
Table 1 – Metal layers for Intel’s 22nm SoC, 14nm SoC, and 22FFL process technologies.
* indicates uni-directional pitches.
‡ indicates multi-patterning.
Compared to 22nm SoC, the 22FFL metal interconnects are much easier for modern EDA tools. Supporting complex shapes in a large number of similar metal layers avoids restrictive design rules and splitting shapes across multiple layers, which enables automated tools to generate denser layouts. This is particularly important for foundry customers, which are not familiar with Intel’s highly restrictive design rules, and for ASIC-like designs (e.g., modems) where clock frequency does not directly translate into value. In contrast, the tapered interconnect hierarchy for the 22nm and 14nm nodes can achieve higher performance, but only by carefully taking advantage of the unique characteristics of each layer, which is difficult for automated tools."
From some digging the 22nm SOC BEOL:
It seems back then what is now called M0 was called M1. That or in intel jargon TCNs are M0, but I have yet to find a clear answer for this floating around the web.
Sorry it isn't a ticket onto a MPW or what the exact options are on i16, but this is what I can find floating around the web. It at least seems to be about as detailed as those europractice GF and TSMC public numbers. But it is obviously less detailed than the full PDKs you already have.
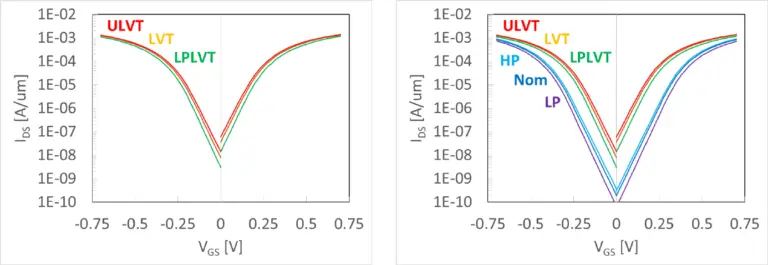

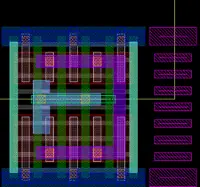
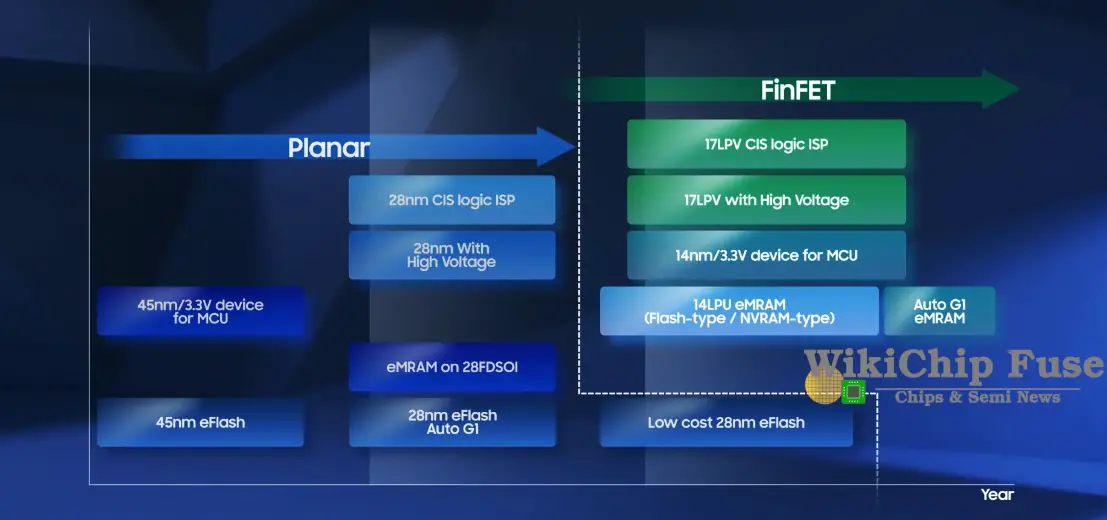

 I don't know man I'm just a chemical engineer.
I don't know man I'm just a chemical engineer.
