Wuhan, China, July 31, 2023 - Terapines Technology, an innovative provider of software/hardware co-design solutions announces the full support for Andes RISC-V processors lineup in the Terapines ZCC toolchain. The ZCC toolchain delivers proven performance gains across multiple end markets, including embedded systems, high-performance computing, and AI. Andes Technology Corporation (TWSE: 6533), a leading supplier of high efficiency, low-power 32/64-bit RISC-V processor cores and Founding Premier member of RISC-V International, has been instrumental in driving RISC-V into the mainstream. Recently, Terapines Technology has joined RISC-V International as a Strategic Member, enabling closer collaboration between these two companies and the overall RISC-V community.
The full support of ZCC toolchain for AndeStar™ V5 Instruction Set Architecture will allow Andes and its silicon partners to achieve higher code density and performance for MCU and SoC products built on the V5 architecture. It opens the door to optimized RISC-V implementations across a wider range of applications.
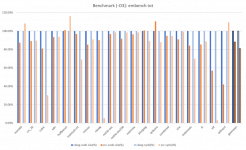
The benchmark results demonstrate the ZCC toolchain's ability to optimize the system performance versus LLVM from AndeSight™ IDE. Based on AndesCore™ AX45 CPU, ZCC achieved a 6% boost over the baseline on CoreMark score, as well as an 18.9% performance improvement and 11.8% better code density on Embench-IoT (-O3). With -Os optimization, Embench-IoT attained a 10% code density gain and 9.1% faster performance.

On the industry-standard SPECInt2006 benchmark, ZCC delivered a 30% lower dynamic instruction count compared to open-source LLVM 16.0 on a RV64GCBV RISC-V processor. It also achieved a 13% lower dynamic instruction count on a RV64GCB RISC-V processor.
These gains showcase the potential of the ZCC toolchain to help engineers maximize efficiency and real-world speedup across a wide variety of RISC-V implementations.

Benchmark results also highlight the powerful auto-vectorization capabilities of ZCC toolchain for AI chip development. ZCC achieved up to 91x higher performance versus open-source compilers on popular computing kernel functions. In some cases, the auto-vectorized output even matched or exceeded hand-optimized assemblies in both performance and efficiency.
These exceptional auto-vectorization results mean ZCC can substantially accelerate AI chip design and lower software maintenance costs. By reducing the need for time-consuming manual optimization of computational kernels, ZCC provides a streamlined path to deploying high-throughput AI accelerators.
Link to Press Release
The full support of ZCC toolchain for AndeStar™ V5 Instruction Set Architecture will allow Andes and its silicon partners to achieve higher code density and performance for MCU and SoC products built on the V5 architecture. It opens the door to optimized RISC-V implementations across a wider range of applications.
The benchmark results demonstrate the ZCC toolchain's ability to optimize the system performance versus LLVM from AndeSight™ IDE. Based on AndesCore™ AX45 CPU, ZCC achieved a 6% boost over the baseline on CoreMark score, as well as an 18.9% performance improvement and 11.8% better code density on Embench-IoT (-O3). With -Os optimization, Embench-IoT attained a 10% code density gain and 9.1% faster performance.
On the industry-standard SPECInt2006 benchmark, ZCC delivered a 30% lower dynamic instruction count compared to open-source LLVM 16.0 on a RV64GCBV RISC-V processor. It also achieved a 13% lower dynamic instruction count on a RV64GCB RISC-V processor.
These gains showcase the potential of the ZCC toolchain to help engineers maximize efficiency and real-world speedup across a wide variety of RISC-V implementations.
Benchmark results also highlight the powerful auto-vectorization capabilities of ZCC toolchain for AI chip development. ZCC achieved up to 91x higher performance versus open-source compilers on popular computing kernel functions. In some cases, the auto-vectorized output even matched or exceeded hand-optimized assemblies in both performance and efficiency.
These exceptional auto-vectorization results mean ZCC can substantially accelerate AI chip design and lower software maintenance costs. By reducing the need for time-consuming manual optimization of computational kernels, ZCC provides a streamlined path to deploying high-throughput AI accelerators.
Link to Press Release