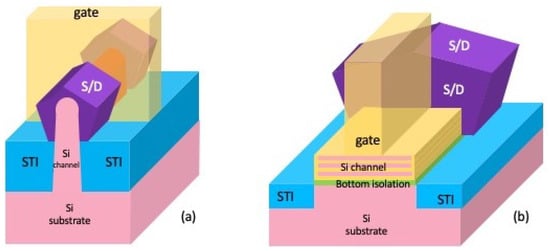
A Review of the Gate-All-Around Nanosheet FET Process Opportunities
In this paper, the innovations in device design of the gate-all-around (GAA) nanosheet FET are reviewed. These innovations span enablement of multiple threshold voltages and bottom dielectric isolation in addition to impact of channel geometry on the overall device performance. Current scaling...



