A recent Anandtech article https://www.anandtech.com/show/21408/tsmc-roadmap-at-a-glance-n3x-n2p-a16-2025-2026 prompted me to do a trend plot for TSMC density scaling by node (starting from N16), also using https://en.wikipedia.org/wiki/5_nm_process and https://en.wikichip.org/wiki/7_nm_lithography_process as reference.
Here is a brief version:
.png")
and here is the full version including more of the N3 and N2 sub-nodes:
.png")
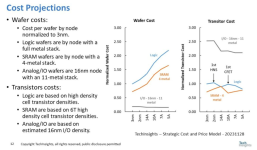
A classic full node scaling should have a density scaling factor of 2, and we start to fall short of that already at 7nm going to 5nm. It continues dropping going to 3nm, and afterwards, there is practically no scaling (to now). We probably saw signs of this already in the flattening of the SRAM cell size trend. Of course, we expect the others like Samsung and Intel to feel the same difficulty.
Here is a brief version:
and here is the full version including more of the N3 and N2 sub-nodes:
A classic full node scaling should have a density scaling factor of 2, and we start to fall short of that already at 7nm going to 5nm. It continues dropping going to 3nm, and afterwards, there is practically no scaling (to now). We probably saw signs of this already in the flattening of the SRAM cell size trend. Of course, we expect the others like Samsung and Intel to feel the same difficulty.
Last edited: