Why does it seem like current FPGA devices work very much like the original telephone systems with exchanges where workers connected calls using cords and plugs? Achronix thinks it is now time to jettison Switch Blocks and adopt a new approach. Their motivation is to improve the suitability of FPGAs to machine learning applications, which means giving them more ASIC-like performance characteristics. There is, however, more to this than just updating how data is moved around on the chip.
Achronix has identified three aspect of FPGAs that need to be improved to make them the preferred choice for implementing machine learning applications. Naturally, they will need to retain their hallmark flexibility and adaptability. The three architecture requirements for efficient data acceleration are compute performance, data movement and memory hierarchy. Achronix took a step back and looked at each element in order to recreate how programmable logic should work in the age of machine learning. Their new Speedster 7t is the result. Their goal was to break the historical bottlenecks that have reduced FPGA efficiency. They call the result FPGA+.
Built on TSMC’s 7nm node these new chips have several important innovations. Just as all our phone calls are now routed with packet technology, Achronix’s Speedster 7t will use a 2 dimensional arrayed network on chip (NoC) to move data between the compute elements, memories and interfaces. The NoC is made up of a grid of master and slave Network Access Points (NAPs). Each row/column operates at 256b @2.0Gbps, a combined 512 Gbps. This puts device level bandwidth in the range of 20Tbps.
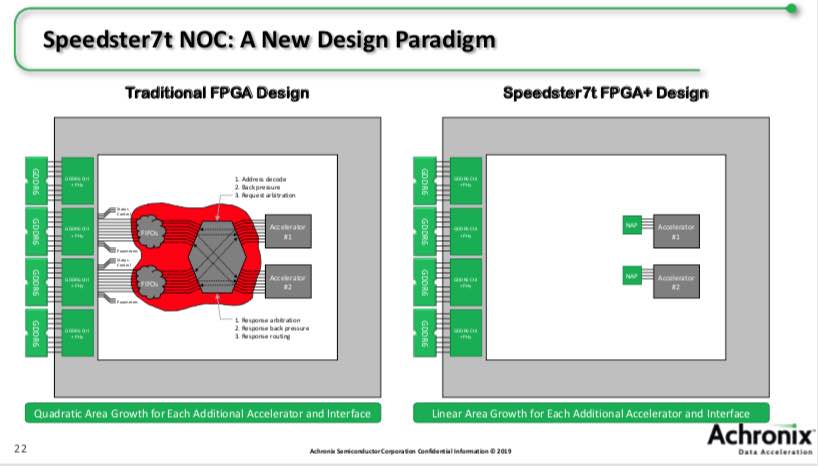
The NoC supports specific connection modes for transactions (AXI), Ethernet packets, unpacketed data streams and NAP to NAP for FPGA internal connections. One benefit of this is that the NoC can be used to preload data into memory from PCIe without involving the processing core. Another advantage is that the network structure removes pressure during placement to position connected logic units near each other, which was a major source of congestion and floor planning headaches.
The NoC also allows the Achronix Speedster 7t to support 400G operation. Instead of having to run a 1000 bit bus at 724 MHz, the Speedster 7t can support 4 parallel 256 bit buses running at 506MHz to easily handle the throughput. This is especially useful when deep header inspection is required.
For peripheral interfaces, the approach that Achronix uses is to offer a highly scalable SerDes that can run from 1 to 112Gbps to support PCIe and Ethernet. They can include up to 72 of these per device. For Ethernet, they can run 4x 100Gbps or 8x 50Gbps. Lower rate Ethernet connections are also supported for back compatibility. They support PCIe Gen5, with up to 512 Gbps per port, with two ports per device.
The real advantage of their architecture becomes apparent when we look at the compute architecture. Rather than have separate DSPs LUTs and block memories, they have combined these into Machine Learning Processors (MLPs). This immediately frees up bandwidth on the FPGA routing. These three elements are used heavily together in machine learning applications, so combining them is a big advantage for their architecture.
AI and ML algorithms are all over the map on the need for mathematical precision. Sometimes large float precision is used, in other cases there has been a move to low precision integer. Google even has their own Bfloat precision. To handle this wide variety, Achronix has developed fracturable float and integer MACs. The support for multiple number formats provides high utilization of MAC resources. The MLPs also include 72Kbit RAM blocks, and memory and operand cascade capabilities.
For AI and ML applications, local memory is important, but so is system RAM. Achronix decided to use GDDR6 on their Speedster 7t family. It offers lower cost, easier and more flexible system design and extremely high bandwidth. Of course DDR4 can be used for less demanding storage needs as well. The use of GDDR6 allows each design to tune their memory needs, rather than being dependent on memory that is configured in the same package as the programmable device. Speedster 7t supports up to 8 devices with throughput of 4 Tbps.
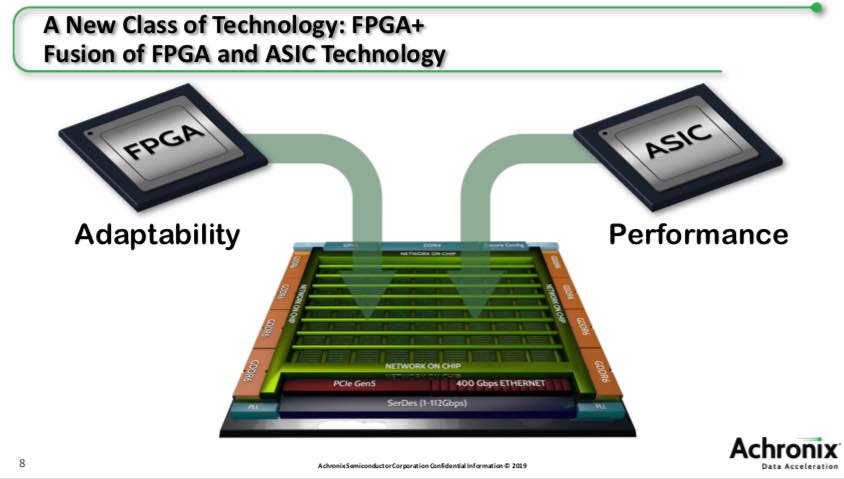
There is a lot to digest in this announcement, it is worth looking over the whole thing. Looking back, this evolution will seem as obvious as how our old wired table top phones evolved into highly connected and integrated communications devices. The take-away is that this level of innovation will lead to unforeseen advances in end product capabilities. According to the Achronix Speedster 7t announcement, their design tools are ready now and they will have a development board ready in Q4.
Share this post via:



Comments
There are no comments yet.
You must register or log in to view/post comments.